
Alfresco Search and Discovery - The Overview
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Blog
- :
- Alfresco Search and Discovery - The Overview
Alfresco Search and Discovery - The Overview
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
9 Jan 2018
1:56 PM
This post is a short technical overview of Alfresco Search and Discovery. It accompanies the related Architect/Developer Whiteboard Video. In a nutshell, the purpose of Search & Discovery is to enable users to find and analyse content quickly regardless of scale.
Below is a visual representation of the key software components that make up Alfresco Search and Discovery.
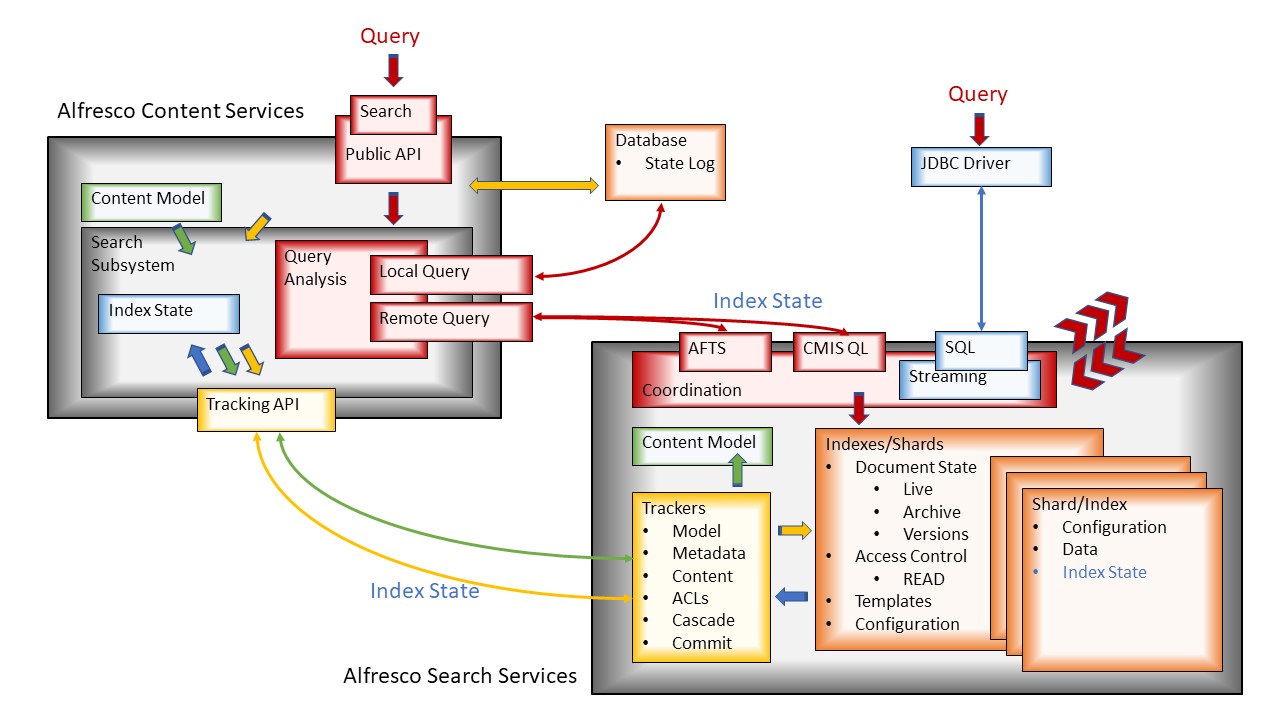
Search and Discovery can be split into five parts:
- a shared data model - components shown in green;
- the index and the underlying data that is created by indexing and used for query - components shown in orange;
- querying those indexes - components shown in red;
- building indexes - components shown in yellow; and
- some enterprise only components shown in blue.
What is an index?
An index is a collection of document and folder states. Each state represents a document or folder at some instance in time. This state includes where the document or folder is filed, its metadata, its content, who has access rights to find it, etc..
The data model that defines how information is stored in the repository also defines how it is indexed and queried. Any changes made to a model in the repository, like adding a property, are reflected in the index and, in this case, the new property is available to query in a seamless and predictable way.
We create three indexes for three different states:
- one for all the live states of folders and content;
- one for all the explicitly versioned states of folders and content; and
- one for all the archived states of folders and content.
It is possible to query any combination of these states.
Each of these indexes can exist as a whole or be broken up into parts, with one or more copies of each part, to meet scalability and resilience requirements. These parts are often referred to as shards and replicas. There are several approaches to breaking up a large index into smaller parts. This is usually driven by some specific customer requirement or use case. The options include: random assignment of folders and documents to a shard, assignment by access control, assignment by a date property, assignment by creation, assignment by a property value, and more. Another blog covers index sharding options in detail.
For example, sequential assignment to a shard at document creation time gives a simple auto-scalable configuration. Use one shard until it is full and then add the next shard when required. Alternatively, if all your queries specify a customer by id it would make sense to split up your data by customer id. All the information for each customer would then be held together in a single shard.
Indexes typically exist as single shard up to around 50M files and folders. Combining all the shards gives an effective overall index. The data, memory, IO load, etc can then distributed in a way that can be scaled. It is common to have more then one replica for each shard to provide scalability, redundancy and resilience.
Search Public API
The search public REST API is a self-describing API that queries the information held in the indexes outlined above. Any single index or combination of indexes can be queried. It supports two query languages. A SQL like query language defined by the CMIS standard and a Google like query language we refer to as Alfresco Full Text Search (AFTS). Both reflect the data model defined in the repository. The API supports aggregation of query results for facet driven navigation, reporting and analysis.
The results of any query and related aggregation always respect the access rights of the user executing the query. This is also true when using Information Governance where security markings are also enforced at query and aggregation time.
The search public API and examples are covered in several existing blogs. See:
For enterprise customers, we support also JDBC access using a subset of SQL via a thin JDBC driver. This allows integration with BI and reporting tools such as Apache Zeppelin.
The Content Model
All indexes on an instance of Alfresco Search Services share the same content model. This content model is a replica of the content model held in Alfresco Content Services. If you add a type, aspect, or property to the content model any data added will be indexed according to the model and be available to query.
The Alfresco full text search query language and CMIS query language are backed by the content model. Any property in the model can be used in either query language. The details of query implementation are hidden behind this schema. We may change the implementation and ”real” index schema in the future but this virtual schema, defined by the data model and the query syntax, will remain the same.
The data model in the repository defines types, aspects and properties. A property type defines much of its index and query behaviour. Text properties in particular require some additional thought when they are defined. It is important to consider how a property will be used.
- … as an identifier?
- … for full text search?
- … for ordering?
- … for faceting and aggregation?
- … for localised search?
- … for locale independent search?
… or any combination of the above.
A model tracker maintains an up to date replica of the repository model on each search services instance.
Building Indexes
When any document is created, updated or deleted the repository keeps a log of when the last change was made in the database. Indexing can use this log to follow state changes in the order those changes were made. Each index, shard or replica records its own log information describing what it has added. This can be compared with the log in the database. The indexing process can replay the changes that have happened on the repository to create an index that represents the current state of the repository and resume this process at any point. The database is the source of truth: the index is a read view optimised for search and discovery.
Trackers compare various aspects of the index log with the database log and work out what information to pull from the database and add to the index state. The ACL tracker fetches read access control information. The metadata for nodes is pulled in batches from the repository in the order in which they were changed by the metadata tracker. If a node includes content, the content tracker adds that to the existing metadata information sometime after the metadata has been indexed. The cascade tracker asynchronously updates any information on descendant nodes when their ancestors change. This cascade is caused by operations such as rename and move, or when ancestors are linked to other nodes creating new structure and new paths to content. The commit tracker ensures that transactional updates made to the database are also transactionally applied to the index. No part transactions are exposed by search and transactions are applied in the order expected. The commit tracker also coordinates how information is added to the index and when and how often it goes live. The index state always reflects a consistent state that existed at some time in the database.
As part of the tracking process, information about each index and shard is sent back to the digital business platform. This information is used to dynamically group shards and replicas into whole indexes for query. Each node in the Digital Business Platform can determine the best overall index to use for queries.
All shards and replicas are built independently based on their own configuration. There is no lead shard that has to coordinate synchronous updates to replicas. Everything is asynchronous. Nothing ever waits for all the replicas of a shard to reach the same state. The available shards and replicas are intelligently assembled into a whole index.
Replicas of shards are allowed to be unbalanced - each shard does not have to have the same number of replicas. Each replica of a shard does not have to be in the same state. It is simple to deal with a hot shard - one that gets significantly more query load than the others - by creating more copies of that shard. For example, your content may be date sensitive with most queries covering recent information. In this case you could shard by date and have more instances of recent shards.
Query Execution
Queries are executed via the search endpoint of the Alfresco REST API or via JDBC. These APIs support anything from simple queries to complex multi-select faceting and reporting use cases. Via the public API each query is first analysed. Some queries can be executed against the database. If this is possible and requested that is what happens. This provides transactional query support. All queries can be executed against one or more Alfresco Search Services instances. Here there is eventual consistency as the index state may not yet have caught up with the database. The index state however always reflects some real consistent state that existed in the database.
When a query reaches an Alfresco Search Services instance it may just execute a query locally to a single index or coordinate the response over the shards that make up an index. This coordination collates the results from many parts to produce an overall result set with the correct ranking, sorting, facet counts, etc.
JDBC based queries always go to the search index and not the database.
Open Source Search
Alfresco Search Services is based on Apache Solr 6, in which Alfresco is a leader. Alfresco is an active member of the Apache SOLR community. For example, we have Joel Bernstein on staff, who is a SOLR committer. He has led the development of the SOLR streaming API and has been involved with adding support for JDBC. Other Alfresco developers have made contributions to SOLR related to document similarity, bug fixes and patches.
Highly Scalable and Resilient Content Repository
These features combine to give a search solution that can scale up and out according to customer needs and is proven to manage one Billion documents and beyond. Customers can find content quickly and easily regardless of the scale of the repository.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Blog
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco Community Edition 23.2 Release Notes
- Decommissioning of Alfresco SVN Instances
- Summarization of textual content in Alfresco repos...
- ACS containers and cgroup v2 in ACS up to 7.2
- Migrating from Search Services to Search Enterpris...
- Alfresco Community Edition 23.1 Release Notes
- Integrating Alfresco with GenAI Stack
- Achieving Higher Metadata Indexing Speed with Elas...
- ACA Extension Development Javascript-Console & Nod...
- Hyland participation in DockerCon 2023
- Alfresco repository performance tuning checklist
- The Architecture of Search Enterprise 3
- Alfresco Identity Service End of Life
- Using ActiveMQ with Alfresco 7.4
- Offline/parallel re-indexing with ElasticSearch
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.