
Index Sharding
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Blog
- :
- Index Sharding
Index Sharding
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
18 Sep 2017
11:44 AM
- Introduction
- Getting started
- Sharding Methods
- By ACL ID v1 (Alfresco Content Services 5.1, Alfresco Search Services 1.0 & 1.1)
- By DBID (Alfresco Search Services 1.0 & 1.1)
- By Date (Alfresco Search Services 1.0 & 1.1)
- By Metadata (Alfresco Search Services 1.0 & 1.1)
- By ACL ID v2 (Alfresco Search Services 1.0 & 1.1)
- By DBID range (Alfresco Search Services 1.1)
- Explicit sharding (Alfresco Search Services 1.2)
- Availability matrix
- Comparison Overview
- Summary
Introduction
At some point, depending on your use case, a SOLR index reaches some maximum size. This could be related to any number of metrics, for example: the total document count, metadata index rate, content index rate, index size on disk, memory requirements, query throughput, cache sizes, query response time, IO load, facet refinement, warming time, etc. When you hit one of those constraints sharding and/or replication may be the solution. There are other reasons to introduce sharding and replicas, for example, fault tolerance, resilience and index administration. There are other configuration changes that could help too. Some other time! This is about sharding.
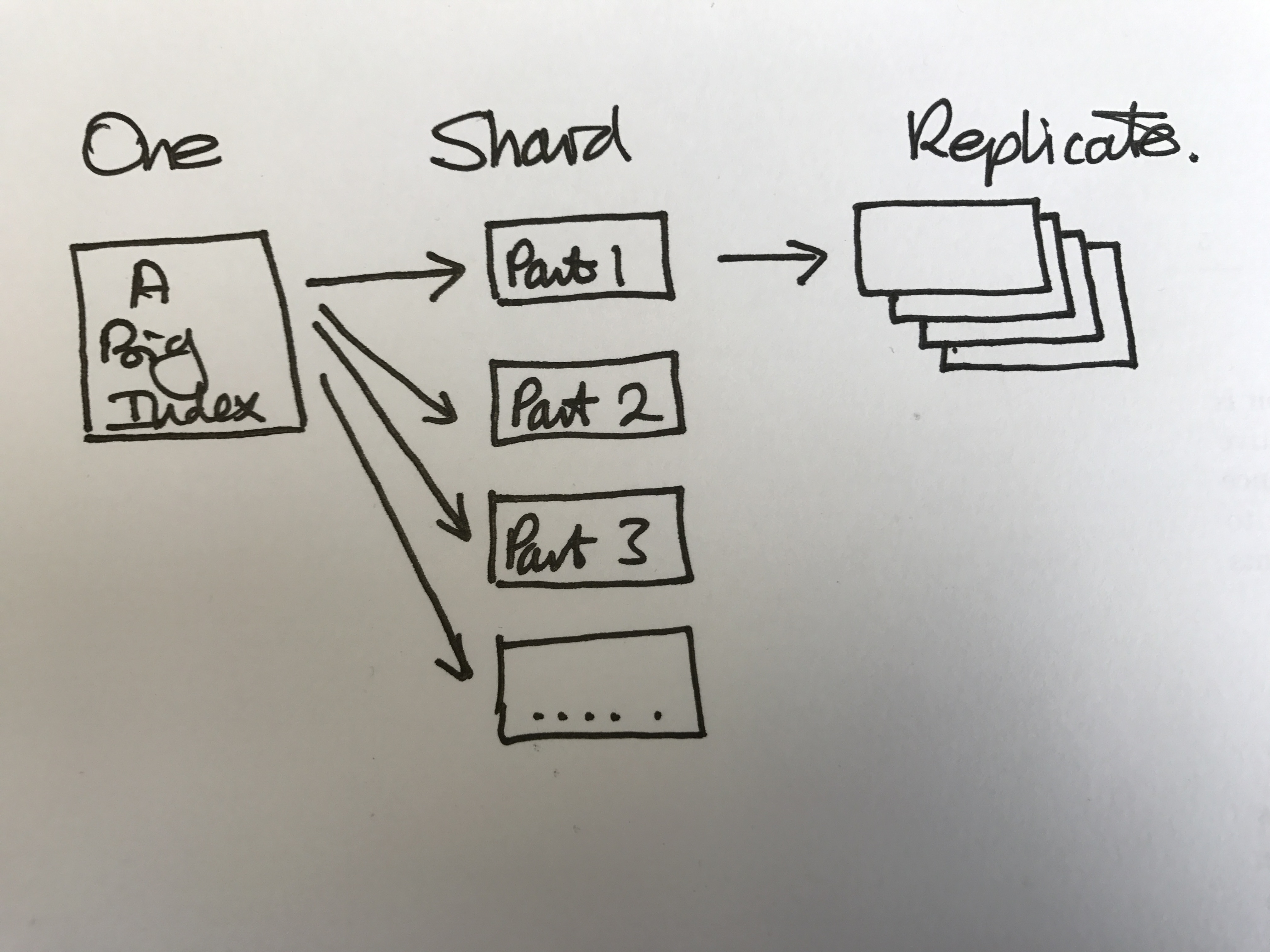
Sharding is not free. It is more complicated to set up and administer than a single, unsharded index. It also requires some planning to determine the number of shards. Executing a query against a sharded index is as fast as the slowest shard response. Faceting often requires a second refinement step to get the numbers exactly right. At worst, adding a facet may double the query cost. Some facets are better than others in this respect. In particular, field facets will generally cause this second step on high cardinality fields. Mostly, performance scales with index size, so splitting your index in half will half the response time from each shard. There are overheads for coordination and particularly for facet refinement. As your shard count grows there are more bits that have to be there. However, at some point sharding is the way to go.
Sharding is there to split your index into parts to scale the size of your index. When you reach your limiting constraint for index size you need to shard. Replication is there to provide multiple copies of the same shard for resilience or throughput. Some issue may be addressed by both. Query execution times can be reduced by reducing the size of the index - by splitting into two halves. You may get to the same point splitting the load over two replicas.
This blog post describes the sharding methods available and when they may be appropriate.
Getting started
First, you will need some ideas about the size of your repository, how it will grow, how your data is made up and how you want to query it.
For Alfresco Content Services 5.1 we carried out a 1 billion+ node scale test in AWS, some aspects of which I will describe next.
But first: this information is indicative and the numbers will vary depending on your use case, sharding and replication strategy, data, configuration, faceting, ordering and a whole host of other things that will not be the same for you. For example, your content tracking will be slower as we did not need to transform content. Ideally you would benchmark the performance of a single shard for your particular use case and environment. Our AWS environment is not yours! AWS marches on at a pace, and so do we, with indexing and permission performance improvements in Alfresco Search Service 1.0 and on. Please take a look at our Scalability Blueprint and refer to the documentation here.
If you did not read the disclaimer above then do so. It's important! For the 1 billion node bench mark against Alfresco Content Service 5.1 using Share, we aimed for a single shard size of around 50M nodes with 20 shards. In fact we got 40-80M nodes because of how ACLs are generated. (ACL ids are now more evenly distributed with the second version of ACL id based sharding.) We wanted to get to size as fast as possible: it did not have to be real persisted content. Most of the content was repeatably generated on the fly, but never the less, representative of real content with respect to index and query. No transformation of content was required. For our data and configuration, 50M nodes was the point where metadata indexing started to fall behind our ingestion rate. Between 10-20M nodes content tracking started to fall behind. We could have rebalanced the metadata/content load but there was no configuration to do this easily at the time. There will be soon. Our indexes were 300-600G on ephemeral disk, SOLR 4 was given 16G and the OS had around 45G to cache parts of the index in memory. IO load initially limited phrase query performance for content so we developed the rerank core. This execute phrase queries as a conjunction query followed by a "re-rank by phrase" operation. We also configured out facets that required refinement and left those based on facet queries. The rerank core had a bunch of additional improvements for scaling which are now the default in Alfresco Search Services 1.0 and on. Again, the details are in the Scalability Blueprint.
Most sharding options are only available using Alfresco Search Services 1.0 and later.
Sharding Methods
With any of the following, if the shard where a node lives changes, it will be removed from the old shard and added to the new. As is the nature of eventual consistency until this completes the node may be seen in the wrong shard, in neither shard or in both shards. Eventually it will only be seen in the right shard.
By ACL ID v1 (Alfresco Content Services 5.1, Alfresco Search Services 1.0 & 1.1)
Nodes and access control lists are grouped by their ACL id. This places nodes together with all the access control information required to determine the access to a node in the same shard. Shards may be more uneven in size than using other methods. Both nodes and access control information are sharded. The overall index size will be smaller then other methods as the ACL index information is not duplicated in every shard. However, the ACL count is usually much smaller than the node count. This method is great if you have lots of ACLs and documents evenly distributed over those ACLs. Heavy users of Share sites and use cases where lots of ACLs are set on content or lots of folders should benefit from this option. If your documents are not well distributed over ACLs, perhaps many millions have the same access rights, there are likely to be better options. So the metrics to consider are the number of nodes / number of ACLs and the number of ACLs with respects to the number of shards. You want many more ACLs than shards and an even distribution of documents over ACLs.
Nodes are assigned to a shard by the modulus of the ACL id. There is better distribution of ACLs over shards using version 2 of ACL id based sharding which uses the murmur hash of the ACL id.
At query time all shardsare used. If the query is constrained to one share site using the default permission configuration the query may only have data in one shard. All but one shard should be fast and no query refinement will be required as all but one shard will give zero results. Ideally we want to hit one shard or a sub-set of shards.
shard.method=MOD_ACL_ID
By DBID (Alfresco Search Services 1.0 & 1.1)
Nodes are distributed over shards at random based on the murmur hash of the DBID. The access control information is duplicated in each shard. The distribution of nodes over each shard is very even and shards grow at the same rate. This is the default sharding option in 5.1. It is also the fall back method if information for any other sharding information is unavailable.
At query time all shards would be expected to find nodes. No query would target a specific shard.
shard.method=DB_ID
By Date (Alfresco Search Services 1.0 & 1.1)
Sharding by date is not quite the same as the rest. The shards are assigned sequentially to buckets with wrap around. It is not random. Some specific age range goes in each bucket. The size of this range can be controlled by configuration.
A typical use case is to manage information governance destruction. If you have to store things for a maximum of 10 years you could shard based on destruction date. However, not everything has a destruction date and things with no shard key are assigned randomly to shards as "by DIDB". So unless everything really does have a destruction date, it is best to stick with the creation date or modification date - everything has one of those.
At query time all shards are used. Date constrained queries may produce results from only a sub set of shards.
To shard over 10 live years 12 shards is a good choice. Using 12 shards has more flexibility to group and distribute shards. You need more than 10 shards and you may have financial years that start in funny places. Of these 12 shards 10 (or 11) will be live - one ready to drop and one ready to be used. When the year moves on the next shard will come into play. One shard will contain all recent nodes. Any shard may see a delete or update. Older shards are likely to change less and have more long lived caching. Most indexing activity is seen by one shard.
The smallest range unit is one month with any number of months grouped together. You could have a shard for every month, pair of months, quarter, half year, year, 2 years, etc.
Some use cases of date sharding may have hot shards. Perhaps you mostly query the last year and much less frequently the rest. This is where dynamic shard registration helps. There is nothing to say that each shard should have the same number of replicas so you can replicate the hot shard and assume that the other shards come back with nothing quickly.
shard.key=cm:createdshard.method=DATE
shard.date.grouping=3
By Metadata (Alfresco Search Services 1.0 & 1.1)
In this method the value of some property is hashed and this hash used to assign the node to a random shard. All nodes with the same property value will be assigned to the same shard. Customer id, case id, or something similar, would be a great metadata key. Again, each shard will duplicate all the ACL information.
At query time all shards are used. Queries using the property used as the partition key may produce results from only a sub set of shards. If you partition by customer id and specify one customer id in the query (ideally as a filter query) only one shard will have any matches.
It is possible to extract a sub-key to hash using a regular expression; to use a fragment of the property value.
Only properties of type d:text, d:date and d:datetime can be used.
shard.key=cm:creator shard.method=PROPERTY
shard.regex=^\d{4}
By ACL ID v2 (Alfresco Search Services 1.0 & 1.1)
This is the same as ACL ID V1 but the murmur hash of the ACL ID is used in preference to its modulus.
This gives better distribution of ACLs over shards. The distribution of documents over ACLs is not affected and can still be skewed.
shard.method=ACL_ID
By DBID range (Alfresco Search Services 1.1)
This is the only option to offer any kind of auto-scaling as opposed to defining your shard count exactly at the start. The other sharding methods required repartitioning in some way. For each shard you specify the range of DBIDs to be included. As your repository grows you can add shards. So you may aim for shards of 20M nodes in size and expect to get to 100M over five years. You could create the first shard for nodes 0-20M, set the max number of shards to 10 and be happy with one shard for a year. As you approach node 20M you can create the next shard for nodes 20M-40M and so on. Again, each shard has all the access control information.
There should be reasonable distribution unless you delete nodes in some age related pattern. Date based queries may produce results from only a sub set of shards as DBID increases monotonically over time.
shard.method=DB_ID_RANGE
shard.range=0-20000000
Explicit sharding (Alfresco Search Services 1.2)
This is similar to sharding by metadata. Rather then hashing the property value, it explicitly defines the shard where the node should go. If the property is absent or an invalid number sharding will fall back to to using the mumur hash of the DBID. Only text field are supported. If the field identifies a shard that does not exist the node will not be indexed anywhere. Nodes are allowed to move shards. You can add, remove or change the property that defines the shard.
shard.method=EXPLICIT_ID
shard.key=
Availability matrix
| Index Engine | ACL v1 | DBID | Date/time | Metadata | ACL v2 | DBID Range | Explicit |
|---|---|---|---|---|---|---|---|
| 5.0 | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| 5.1 + SOLR 4 | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | |
| 5.2.0 + SOLR 4 | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| 5.2.0 + Alfresco Search Services 1.0 | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ |
| 5.2.1 + Alfresco Search Services 1.1 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| 5.2.1 + Alfresco Search Services 1.2 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
Comparison Overview
| Feature | ACL v1 | DBID | Date/time | Metadata | ACL v2 | DBID Range | Explicit |
|---|---|---|---|---|---|---|---|
| All shards required | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ |
| ACLs replicated on all shards | ✘ | ✔ | ✔ | ✔ | ✘ | ✔ | ✔ |
| Can add shards as the index grows | ✘ | ✘ | ✘ | ✘ | ✘ | ✔ | ✘ |
| Even shards | ✔ | ✔✔✔ | ✔✔ | ✔✔ | ✔✔ | ✔✔ | ✔✔ |
| Falls back to DBID sharding | ✘ | ✘ | ✔ | ✔ | ✘ | ✘ | ✔ |
| One shard gets new content | ✘ | ✘ | Possible | Possible | ✘ | ✔ | ✘ |
| Query may use one shard | ✘ | ✘ | Possible | Possible | ✘ | Possible | ✘ |
| Has Admin advantages | ✘ | ✘ | Possible | ✘ | ✘ | ✘ | Possible |
| Nodes can move shard | ✔ | ✘ | ✔ | ✔ | ✔ | ✘ | ✔ |
Summary
A bit of planning is required to determine the evolution of your repository over time and determine your sharding requirements. There are many factors that may affect your choice. Benchmarking a representative shard will tell you lots of interesting stuff and help with the choices for your data and use case. Getting it wrong is not the end of the world. You can always rebuild with a different number of shards or change your sharding strategy.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Blog
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Join the Alfresco TechQuest Hack-a-thon 2024: Inno...
- History of Alfresco Versions
- Alfresco in the OpenSearchCon Europe 2024
- Alfresco Community Edition 23.2 Release Notes
- Decommissioning of Alfresco SVN Instances
- Summarization of textual content in Alfresco repos...
- ACS containers and cgroup v2 in ACS up to 7.2
- Migrating from Search Services to Search Enterpris...
- Alfresco Community Edition 23.1 Release Notes
- Integrating Alfresco with GenAI Stack
- Achieving Higher Metadata Indexing Speed with Elas...
- ACA Extension Development Javascript-Console & Nod...
- Hyland participation in DockerCon 2023
- Alfresco repository performance tuning checklist
- The Architecture of Search Enterprise 3
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.