
Missing embedded metadata when uploading PDF
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Forum
- :
- Missing embedded metadata when uploading PDF
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Missing embedded metadata when uploading PDF
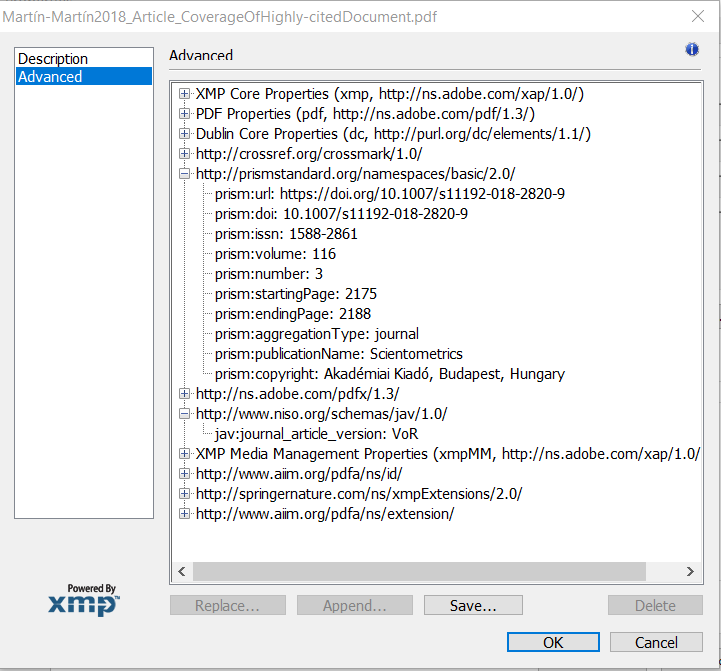
Hello, I'm trying to automate metadata extraction in Alfresco Community 5.2 so that my custom models get populated automatically when documents are uploaded. My PDFs have custom embedded metadata fields (see image 1). However, when I import these PDFs to Alfresco, according to the information in the alfresco debugger, not all the metadata tags (for example prims: and jav![]() are detected (see image 2). Do you know if this is the expected behaviour? In that case, what do I have to change so that Alfresco detects these custom metadata fields? Thank you very much for your help in advance.
are detected (see image 2). Do you know if this is the expected behaviour? In that case, what do I have to change so that Alfresco detects these custom metadata fields? Thank you very much for your help in advance.

Labels
2 Replies
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Re: Missing embedded metadata when uploading PDF
Check the docs:
Metadata Extractors | Alfresco Documentation
By default, the metadata extraction grabs the author, title, subject, and created. If you want anything else, you'll have to tweak the metadata extractor. Because there is already an extractor that knows how to pull fields from PDFs you should not have to write your own from scratch, but you could if you needed to.
I think you'll just need to map the fields to actual properties in your model. The docs are pretty thorough on this topic and there are a number of other pages around the net that discuss customizing metadata extraction.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Re: Missing embedded metadata when uploading PDF
Hello Jeff, first of all thank your very much for your response.
I'm sorry, I see now that I didn't make myself clear. I read that page of the documentation carefully. I'm writing because I think that while following the instructions in the documentation, I am experiencing a behaviour that I haven't seen discussed in said documentation, or any other document on the web that I could find. I understand that by default, only some fields are mapped, so I wanted to map the fields I need. First, of course, I created a new model that contains a custom type with the fields I needed (for example: DOI, volume, issn), and created a rule in the folder so that any document added to that folder would be specialized to that type.
Then, I needed to create a new mapping, but for that, first I needed to know the names of the properties according to Alfresco. To do this, I modified the log4j.properties so that log4j.logger.org.alfresco.repo.content.metadata.AbstractMappingMetadataExtracter=debug. With this, after uploading a document that contains the metadata I need, I could check the names of the properties I should use in the mapping.
This is where I found my problem. In the Alfresco log file, when I upload one of these documents, not all the metadata that is available in the PDF (see image 1 in first post of the thread) appears as a raw property. For example:
Raw Properties: {date=2018-08-13T08:56:21Z, pdf
DFVersion=1.6, xmp:CreatorTool=Springer, Keywords=Highly-cited documents,Google Scholar,Web of Science,Scopus,Coverage,Academic journals,Classic Papers, subject=Scientometrics, https://doi.org/10.1007/s11192-018-2820-9, pdfa
My main question is, why is Alfresco not detecting all available metadata in the PDF as raw properties?
I tried changing the mapping in the custom-repository-context.xml file anyway, trying to guess the name of the properties that don't appear in the list of raw properties. I tried mapping the DOI (which is available in the raw properties), the volume, and the ISSN (which are not available as raw properties):
<bean id="extracter.PDFBox" class="org.alfresco.repo.content.metadata.PdfBoxMetadataExtracter"
parent="baseMetadataExtracter">
<property name="documentSelector" ref="pdfBoxEmbededDocumentSelector" />
<property name="inheritDefaultMapping">
<value>true</value>
</property>
<property name="mappingProperties">
<props>
<prop key="namespace.prefix.prism">http://prismstandard.org/namespaces/basic/2.0</prop>
<prop key="doi">prism:doi</prop>
<prop key="prism:volume">prism:volume</prop>
<prop key="issn">prism:issn</prop>
</props>
</property>
</bean>
After uploading another document with this configuration in place, as I expected and feared, only the DOI was correctly extracted.
Any ideas as to why some metadata from the PDF is not being detected by Alfresco?
Thank you very much for your help in advance.
Alfresco Content Services Forum
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Where is the file that contains the JMS configurat...
- How to know the folder which triggered action
- Problem Size: Converting Document at PDF/A (label....
- How to call search api from surf webscript (share ...
- How to remove alfresco default properties for any ...
- Syntax for searching datetime property in Postman
- Full Text Search in Community 7.x
- Filtering people according mail
- People dashlet
- Manage rules in the alfresco 7.4 community I Need ...
- Alfresco Community v4.0 (2012), Ubuntu 12.04, Mysq...
- Metadata extraction not working
- Enterprise Pricing 2024
- Reference Architecture for 23.x
- Endpoint liveness/readiness probes for Alfresco Se...
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.