
Packet Beat on my Alfresco - Insane numbers
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Forum
- :
- Packet Beat on my Alfresco - Insane numbers
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Packet Beat on my Alfresco - Insane numbers
I have enabled Packet Beat on my Alfresco and my Confluence Server
Its 2 public sites with very little activity, the Alfresco is only for me.
Even though, the Alfresco generates 1,5 Millions SQL "statements" over 24 hours.... that is insane..
Why...
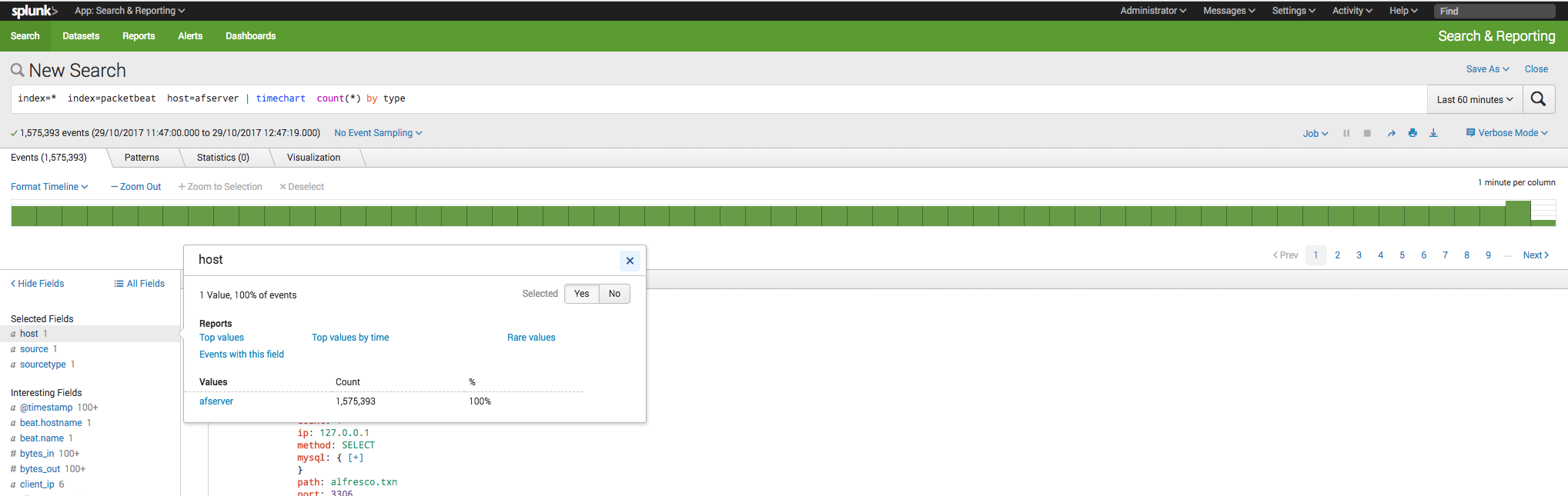{kind=link}
{kind=link}
3 Replies
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Re: Packet Beat on my Alfresco - Insane numbers
I don't consider the raw number that insane really, unless you are able to drill down the number to individual types of queries that can be correlated with feature sets that should not be used. Alfresco includes a variety of background processes that are scheduled to run in regular intervals, e.g. SOLR index tracking which gets triggered ever 15 seconds. Due to the normalisation of data in the database, various interactions require multiple SQL statements to be run in short succession.
The graph you included appears to be very consistent with regards to the number of statements per minute. Is there a way to get an overview over an entire 24 hour period so you can check if there is a specific time when a background process may be triggered that skews the overall number? With 1.5 million statements, you have an average of ~17 per second, which may sound high for a under-utilised system unless you can account for any spikes / background processes.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Re: Packet Beat on my Alfresco - Insane numbers
Well, everybody has a right to a opinion, but its insane, I will stille claim that. A system not used for 24 hours at all (as in: No content change), performs 1,5 mill SQL statements and indexes every 15 seconds ... is that full indexing each time.
I have a Confluence running beside the Alfresco, it like 700 SQL statements over 24 hours - and only indexing when content is updated. As an Operations man looking into I/O and CPU/Memory - the Alfresco is a "waste" of ressources.
Heres 7 days of packet log - 66 millions ... for a system virtually not used...
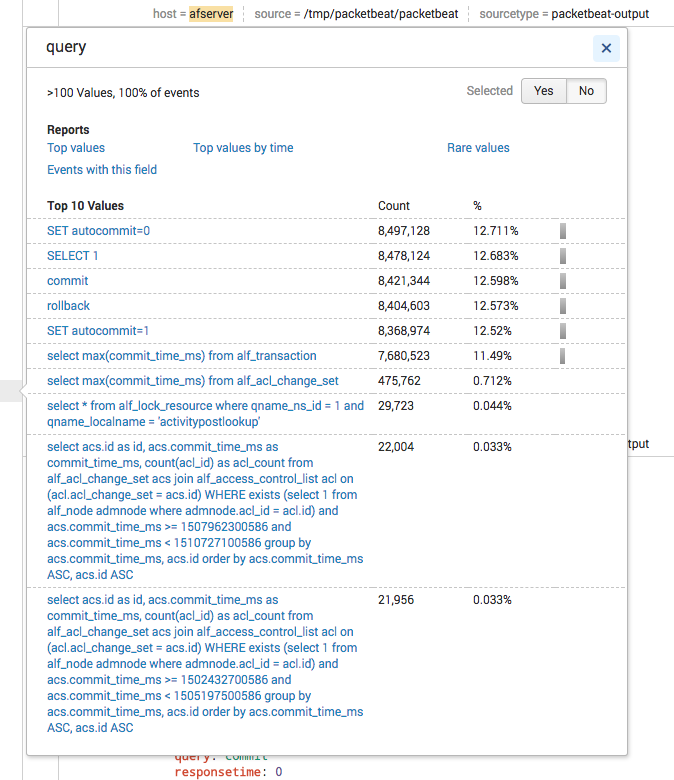
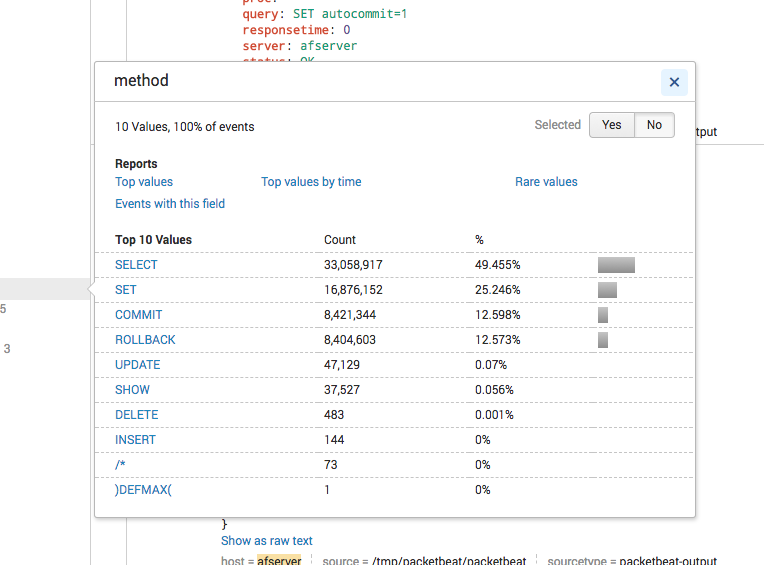
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Re: Packet Beat on my Alfresco - Insane numbers
So those packets all relate to either the general overhead of JDBC connection pool management (obtaining a connection, validating it, commit/rollback handling) or mostly index tracking. The numbers for rollback and select ... from alf_transaction are unnaturally high. Instead of ~8 million they should be at around ~80.000 with the default configuration (actually, there shouldn't be any rollback during idle). The high numbers for the other aspects related to connection management are likely just a result of the rollback and retry functionality within Alfresco.
By activating debug logging for org.alfresco.repo.transaction.RetryingTransactionHelper you'll likely see in the application log what (temporary) errors may cause Alfresco to trigger a rollback + retry. You should find the output in the alfresco.log file.
My statement regarding "sanity" was in the context of the Alfresco application / architecture, not in comparison with other applications. Just as Confluence, Alfresco was once architected to only index when data actually changes, which provided a significantly smaller idle footprint but did not scale well enough for larger system installations. Alfresco was never designed / intended / optimised for a single-person/mostly-idle use case, rather it focuses on hundreds and thousands of users and efficiently dealing with consistent load as a core application in an organisation.
Alfresco Content Services Forum
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco don't start on tomcat 9
- Where is the file that contains the JMS configurat...
- Alfresco don't start on tomcat 9
- Need Urgent Advise: Inconsistent Content Store
- Where is the file that contains the JMS configurat...
- How to know the folder which triggered action
- Problem Size: Converting Document at PDF/A (label....
- How to call search api from surf webscript (share ...
- How to remove alfresco default properties for any ...
- Syntax for searching datetime property in Postman
- Full Text Search in Community 7.x
- Filtering people according mail
- People dashlet
- Manage rules in the alfresco 7.4 community I Need ...
- Alfresco Community v4.0 (2012), Ubuntu 12.04, Mysq...
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.