
Alfresco Repository Architecture
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Hub Docs
- :
- Alfresco Repository Architecture
Alfresco Repository Architecture
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
6 Jun 2015
0:40 AM
Obsolete Pages{{Obsolete}}
The official documentation is at: http://docs.alfresco.com
OverviewArchitectureCore Repository Services
Alfresco is an open source Enterprise Content Management system. It's primarily implemented in Java, suited to a number of environments including J2EE and brings together the best of other open source projects in order to provide a complete set of Content Management solutions. It is not tied to any particular web browser, operating system, application server or database.
This document describes the Alfresco architecture in the form of a high level overview of the available components and their interactions, with a focus on the Alfresco Repository.
Note: A complementary document describing the Alfresco Application architecture will be provided at some point.
Table of Contents
- 1 Inside an Installed Alfresco
- 2 Components & Service APIs - Spring Framework
- 3 A Triplet of Key Foundation Services
- 4 Content Domain Foundation Services
- 5 Which Protocol Shall I Use Today?
- 6 How many APIs? Am I seeing triple?
- 7 Repository Deployment Options
- 8 Summary: Key advantages of the Alfresco Repository Architecture
- 9 Further Reading
- 10 Nodes and Content Models
- 11 Node References and Store Types
- 12 Triggers and Stored Procedures
- 13 Authentication
Inside an Installed Alfresco
Out-of-the-box, Alfresco's simple installation procedure provides a pre-configured deployment. It allows reaching a complete and working Content Management application quickly and easily. The deployment is as follows:
Alfresco Repository Architecture diagram1 colored.png
{kind=link}
This is typical of a web architecture, where an application server houses the logic for both the user interface and domain model. Storage of data and content is provided by persistent back-ends such as databases and file systems. Any number of web browsers can connect to the application without installing anything on the client.
In the diagram above, the application server houses both the Alfresco Application and the Alfresco Repository. An Alfresco Application provides a complete solution tailored for a specific area of Content Management such as Document Management (DM), Web Content Management (WCM) and Records Management (RM). The Alfresco Repository provides a set of reusable cross-cutting Content Management services such as content storage, query, versioning and content transformation. These services may be utilized by multiple applications.
The default installed deployment is only one of many ways of utilizing the capabilities and components of Alfresco. When we first set out to design Alfresco, we wanted to break away from the mould of typical Content Management architectures which are monolithic and closed. The result is that Alfresco can neatly fit into existing environments. Each of its components may be used in isolation or together to form the basis of many differing Content Management solutions.
The remainder of this document explores the anatomy of the Alfresco Repository. It will give you a good understanding of the repository concepts and how it achieves openness, scalability and flexibility.
Components & Service APIs - Spring Framework
Every part of the Alfresco Repository is either a component or a service. A component is an implementation black box that provides a specific feature or capability. A service is an interface entry point for a client to bind to and use. This fundamental approach allows for existing components to be switched with new implementations, new components to be added with ease and for clients to connect and use services without knowledge of how they're implemented.
This extensibility and configurability is achieved using the Spring Framework, a de-facto standard enterprise open source framework. Alfresco has made Spring the core foundation of its architecture. Alfresco components are declaratively configured and bound together using Spring configuration. Aspect-oriented programming features of Spring allows the weaving of infrastructure concerns such as Transactions and Security into components without duplicating functionality. Environment touch points are abstracted, for example database connections.
If there's a feature of Alfresco you don't need, you can disable it through configuration, providing a lighter and possibly faster application. If there's a feature you decide to re-implement, you can easily swap in the new functionality through Spring configuration.
The Alfresco Repository structure looks like this:
Alfresco Repository Architecture diagram2 colored.png
{kind=link}
The public interface point is the Alfresco Repository Foundation Services. Each service is exposed as a Java Interface to which a Repository client can bind and invoke without knowledge of its underlying implementation. A Service Registry lists the available services. Behind services are the implementation black boxes i.e. components. Each service and component is configured via the Spring framework in XML configuration or 'context' files.
Note: The configuration and binding of the Alfresco Repository Foundation Services are defined in the Spring file 'public-services-context.xml'
The Repository Foundation Services are the lowest level of public interface providing access to all Repository capabilities. Binding to this interface is possible via the Repository Service Registry, or via Spring dependency injection if the client is also Spring aware. Access to Foundation Services is limited to Repository clients who reside in the same process as the Repository. That is, the Foundation Services are an excellent API for clients who wish to embed the Repository.
A key point is that the Foundation Services are where transaction and security policies are enforced. The policies themselves are declaratively specified and enforced for each service. Every service of Alfresco is transactional and secure.
Alfresco supports a standard way for making extensions to the Repository i.e. configuring a component, adding a new component or service, or removing components. Extensions are encapsulated outside of the core Repository and plugged-in automatically. This means the core Repository can be upgraded to a newer version and extensions remain intact.
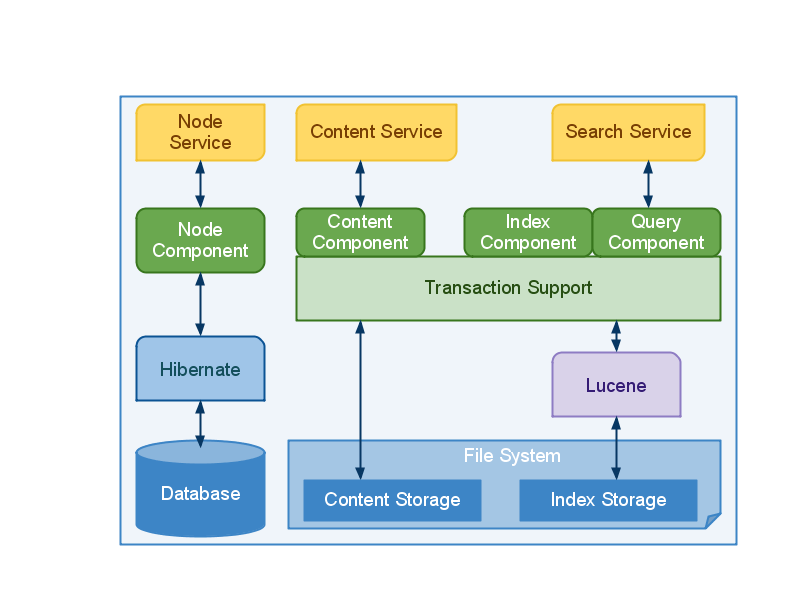
A Triplet of Key Foundation Services
Alfresco Repository is responsible for the storage and retrieval of content. This responsibility is provided by the following three Foundation Services:
- Nodes provide meta-data and structure to content. A node may support properties (e.g. author) and relate to other nodes (e.g. represent folder hierarchies or annotations).
- Content is the actual information being recorded e.g. a Word document or XML fragment. Meta-data and content may be structured according to the rules defined in a Content Model. For example, the Alfresco Document Management application relies on a model that describes Folders and Files.
- Search Service - handles indexing information and allows the retrieval of meta-data and content via many different lookup options.
By default, Alfresco has chosen to store meta-data in a database and content in a file system. Using a database immediately brings in the benefits of databases that have been developed over many years such as transaction support, scaling & administration capabilities. Content is stored in the file system to allow for very large content, random access, streaming and options for different storage devices.
The Alfresco out-of-the-box implementations of the above services are built upon strong open source projects that already have many man-years of development effort and strong communities: Hibernate and Lucene.
Alfresco Repository Architecture diagram3 colored.png
{kind=link}
In addition to the strong Object/Relational mapping that Hibernate provides, it also brings pluggable caching support and SQL dialects. The first allows for tuning of the Alfresco meta-data store to provide optimum read and write performance in both single and clustered environments. The second allows support for nearly any SQL database back-end through easy configuration. The Alfresco community has already confirmed working support for MySQL, Oracle, DB2, Sybase, SQL Server�
By externalising the indexing of meta-data and content and using the Lucene engine as a basis, it is possible to perform complex queries which combine property, location, classification and full-text predicates in a single query against any content type. Multiple query languages are supported. These include Lucene's native language, XPath and a SQL-like language (in the future). To ensure reliable operation, transactional support has been added to both Lucene and the content file store providing ACID operations across the complete store. Security is woven into each of the service layer ensuring illegal modifications are not permissible and hidden meta-data and content are not returned.
Nearly all other services (currently roughly 20) and clients rely upon these three core Foundation Services. Developers need to have a good understanding of Foundation Services.
Content Domain Foundation Services
Building on the key storage and retrieval services, the Alfresco Repository also provides:
- Content Transformation
- Meta-data Extraction
- Templating
- Classification
- Versioning
- Locking
- Content Modeling
- Image manipulation
- Workflow
- Import & Export Services
- Permissions
- TODO: Complete!
They're all implemented using the common component architecture described above and therefore share the same transaction, security and configuration characteristics.
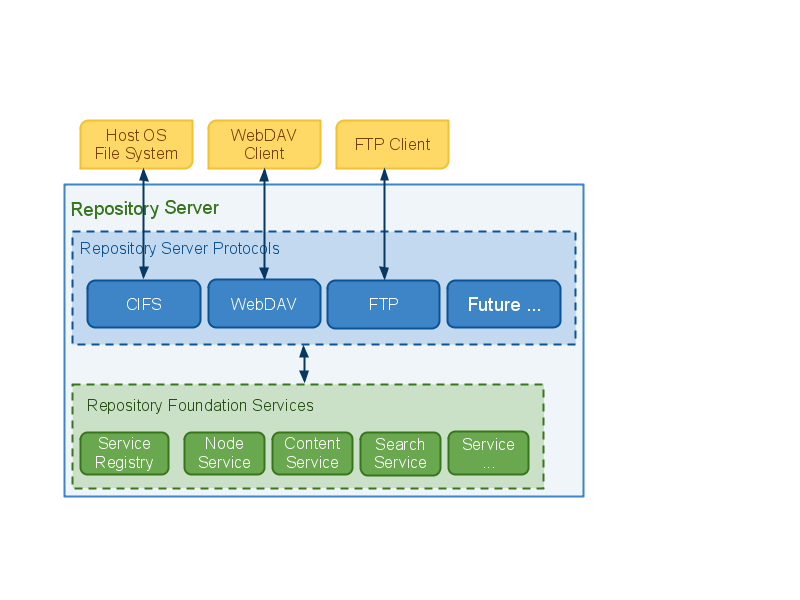
Which Protocol Shall I Use Today?
A Repository is useless if the content it manages cannot be accessed. Alfresco Repository supports a variety of communication protocols. These are:
- CIFS (Common Internet File System)
- WebDAV
- FTP
All of these protocols expose the paradigm of Folders of Files, which maps neatly onto Folder and File nodes held in the Repository (as described by the Document Management content model).
WebDAV and FTP are well known protocols, but CIFS deserves some more attention. CIFS transforms the Alfresco Repository into a standard file system. Thus any tool that understands how to read and write to a file system also knows how to directly read and write to the Alfresco Repository. On the surface, it appears that a drive mapping to WebDAV provides an equivalent capability, but this isn't the case. CIFS projects an actual file system giving extra compatibility with the hosting operating system. For example, in Windows, it's possible to use Offline Synchronization and Briefcase features against the Alfresco Repository for offline working. Many commercial CMS offerings do not provide this feature. In fact, Alfresco may have the only server-side Java implementation of the CIFS protocol having brought on board the engineers who spent 7 years developing such a capability.
IMPORTANT Alfresco does not currently support Offline Synchronization for MS Vista.
Alfresco Repository Architecture diagram4 colored.png
{kind=link}
Like every other feature of the Repository, the protocol components are Spring-configured and as with all other components may or may not be included in a deployment. Typically, they are enabled when the Repository is deployed as a server to provide access points for remote clients. The various Repository deployment options are explored later in this document.
Protocol components are implemented against the Repository Foundation Services. This is important to note, as each protocol will honour the behaviour and content logic encapsulated behind the Foundation Services. In fact, it cannot be bypassed.
How many APIs? Am I seeing triple?
The Alfresco Repository actually provides three APIs. We've already seen one - the Repository Foundation Services - a set of local Java Interfaces covering all capabilities which are ideal for clients who wish to embed the Repository. The other two APIs are built on top of the Foundation Services, and thus take full advantage of the encapsulated content model logic and rules. The two other APIs are:
- Java Content Repository (JCR) API (JSR-170)
- Web Services
JCR (Content Repository API for Java Technologies) is a standard Java API (as defined by JSR-170) for accessing Content Repositories. Alfresco provides support for JCR level 1 and level 2 giving standardised read and write access. Supporting this API provides the following benefits:
- Low risk: The Alfresco Repository can be evaluated and developed against, but swapped out with another JCR Repository if it does not fit customer requirements.
- Familiarity: Developers who know JCR, know Alfresco.
- Tools: Tools, Clients and other 3rd Party JCR solutions are immediately available to the Alfresco community.
Alfresco JCR is implemented as a light facade on top of the Repository Foundation Services. So, although a familiar API is provided, it sits upon a fully transactional, secure and scalable Repository which supports many deployment options. Alfresco will continue investment in JCR by both broadening the compliance of the full specification as well driving forward JSR-283, the next version of the JCR.
Web Services is the final API provided by the Alfresco Repository. This API supports remote access and bindings to any client environment, not just Java. For example, the Alfresco community is already using PHP, Ruby and Microsoft .NET. Numerous standards and integration efforts are focused around Web Services - SOA is now recognised as a way forward for integrating disparate enterprise systems including Content Management. BPEL plays an important role in orchestrating all of these services. Alfresco fits neatly into this way of thinking.
Alfresco repository architecture diagram5.jpg
{kind=link}
Repository Deployment Options
Alfresco Repository is designed to be deployed in a variety of environments and deployment topologies. Much of support for this comes from the Spring Framework. It provides an abstraction layer around most low level services and allows to bind dependencies into the Alfresco Repository, rather than the Repository have explicit knowledge of its environment.
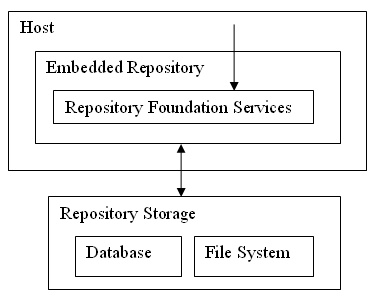
1. Embedded Repository
Alfresco repository architecture diagram6.jpg
{kind=link}
An Embedded Repository is contained directly within a host where the host communicates with the Repository in the same process via the Repository Foundation Services. Typical hosts include content-rich Client applications that require content-oriented storage, retrieval and services. Other hosts include test harnesses and Repository client samples. These usually initialise a Repository on start-up and then close the Repository on shut-down.
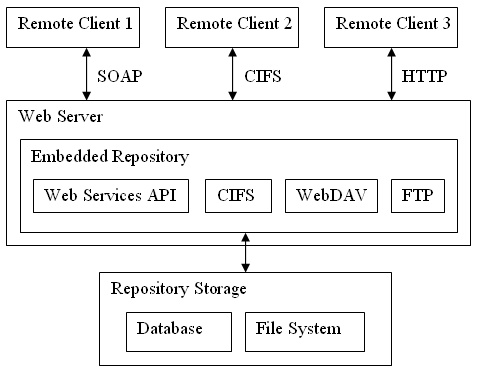
2. Repository Server
Alfresco repository architecture diagram7.jpg
{kind=link}
A Repository Server is a stand-alone server capable of servicing requests over remote protocols and providing appropriate responses. A single server can support any number of different applications and clients. New applications may be added arbitrarily. Each deployment can choose which of the protocols are supported by configuring out unwanted ones. Web Server features such as transaction management and resource pooling are injected into the Repository so it can take advantage of them. This means the Repository automatically benefits from any enhanced features provided by higher-end web application servers. For example, the Repository can be embedded inside Apache Tomcat for the lightest weight deployment, but also embedded inside J2EE compliant application servers from JBoss, Oracle or IBM to take advantage of distributed transactions etc.
2a. Repository Application Server
This deployment is a specialisation of deployment option 2. The Repository is still deployed within a Web Server, but instead of exposing a set of remote protocols for client communication, a Web Application is bundled instead. Essentially, the Web Application becomes the host for an embedded Repository and remote access is via the Application i.e. HTTP. This is the default deployment option chosen by the Alfresco installer as described right back at the start of this document. Of course, any of the Repository remote protocols may also be exposed.
3. Clustered Repository Server
Alfresco repository architecture diagram8.jpg
{kind=link}
A Clustered Repository Server supports large numbers of requests by employing multiple processes against a single Repository store. Each Embedded Repository is hosted in its own Web Server and the collection as a whole (i.e. the Cluster) acts as a single Repository. This kind of deployment is only possible because of the hooks the Repository has into external distributed transaction managers and sophisticated distributed caches.
4. Hot Backup
Alfresco repository architecture diagram9.jpg
{kind=link}
In this deployment, one Repository Server is designated the Master and another completely separate Repository Server is designated the Slave. The �live� application is hosted on the Master and as it is used, synchronous and asynchronous replication updates are made to the Slave i.e. the backup. The backup remains in read-only mode. If for some reason, the Master breaks down, it is a relatively simple task to swap over to the Slave to continue operation.
5. Federated Repositories
This option will be supported in the future.
Summary: Key advantages of the Alfresco Repository Architecture
- Open component architecture - remove what you don't need, replace what you don't like
- Transactional across all Services
- Secure across all Services
- Fine-grained Permissions
- High-level content management services e.g. transformation, templating, meta-data extraction
- Accessible from any environment (e.g. Java, PHP, .NET)
- Accessible to any client (e.g. FTP, WebDAV, HTTP)
- Deployable to any environment - any application server, database and operating system
- Multiple Deployment Topologies
- Native File System Support
- Offline Synchronisation and Briefcase support
- Scale-out via Clustering
- Risk free: Standards support e.g. JSR-170
- Built upon best of breed open source projects time-tested in the enterprise
- Extensible
- Stored procedures and Triggers e.g. Policies, Rules & Actions
- Workflow support
- SOA ready
- Rich content modelling
- Pluggable storage back-ends
- Hot backup support
- Open source and community backed
- Supported by the leading open source out-of-the-box Content Management Applications in Document Management and soon Web Content Management
Further Reading
- Server Configuration - links to a lot of server configuration pages
- Repository Configuration
- Content Store Configuration
TODO: Add references to appropriate WIKI pages.
Nodes and Content Models
TODO:
Node References and Store Types
TODO:
Triggers and Stored Procedures
TODO:
- policies
- rules
- actions
Authentication
TODO:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Hub Docs
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco Community Edition 201911 GA Release Notes
- Alfresco Community Edition 201910 EA Release Notes
- Deconstructing SOLR Indexes
- Alfresco Community Edition 201901 GA Release Notes
- Alfresco Community Edition 201808 EA file list
- php_upload.docx
- Alfresco Community Edition 201808 EA Release Notes
- Alfresco_6.0_docker deployment.pdf
- Alfresco Community Edition 201806 GA file list
- alfresco.log
- Alfresco Addons *Incomplete list*
- Alfresco Community Edition 201806 GA Release Notes
- AGS Benchmark Driver Documentation
- Default memory allocation issue in Alfresco CE 201...
- Alfresco Community Edition 201804 EA file list
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.