
Cluster Configuration V1.4 to V2.1.2
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Hub Docs
- :
- Cluster Configuration V1.4 to V2.1.2
Cluster Configuration V1.4 to V2.1.2
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
6 Jun 2015
0:40 AM
Obsolete Pages{{Obsolete}}
The official documentation is at: http://docs.alfresco.com
High Availability
Back to Server Configuration
Table of Contents
Introduction
This page aims to describe some of the components and configuration options available for high availability and backup. Sample configurations or configuration snippets that arise from real-world solutions will be given. There will be many combinations of configurations and levels of complexity left out. Feel free to contribute further examples.
The configurations here apply to Alfresco V1.4 onwards, i.e. the document repository configurations remain the same in V2.0. However, WCM capabilities in V2.0 are not included in the cluster configurations and are not supported. WCM clustering is planned for V2.1.
BUG: Bug AR-1412 means that it is necessary to run at least 1.4.3 to guarantee index consistency when a machine is brought back online after a period of inactivity.
NOTE: This document assumes knowledge of how to extend the server configuration. (Repository Configuration)
The following naming convention applies:
- <configRoot> - the location of the default configuration files for a standard Alfresco installation (e.g. file <configRoot>/alfresco/application-context.xml)
- <extConfigRoot> - the externally located configuration location (e.g. file <extConfigRoot>/alfresco/extension/custom-repository-context.xml)
NOTE RivetLogic, an Alfresco partner company, wrote a page about deploying HA on Linux for their clients here.
High Availability Components
Client Session Replication
This is not supported by the Alfresco web client at present.
Content Store Replication
The underlying content binaries are distributed by either sharing a common content store between all machines in a cluster or by replicating content between the clustered machines and a shared store(s).
Index Synchronization
The indexes provide searchable references to all nodes in Alfresco. The index store is transaction-aware and cannot be shared between servers. The indexes can be recreated from references to the database tables. In order to keep the indexes up to date (indicated by boxes ‘Index A’ and ‘Index B’) a timed thread updates each index directly from the database. When a node is created (this may be a user node, content node, space node, etc) metadata is indexed and the transaction information is persisted in the database. When the synchronization thread runs, the index for the node is updated using the transaction information stored in the database.
Cache Replication
The Level 2 cache provides out-of-transaction caching of java objects inside the alfresco system. Alfresco only provides support for EHCache. This guide describes the synchronisation of EHCache across clusters. Using EHCache does not restrict the Alfresco system to any particular application server, so it is completely portable.
Database Synchronisation
It is possible to have co-located databases which synchronize with each other. This guide describes the setup for a shared database. If you wish to use co-located databases then refer to your database vendor’s documentation to do this.
Scenarios
Sticky Client Sessions with Simple Repository Clustering
{kind=link}
Scenario
- Single, shared content store
- Sticky client sessions without login failover
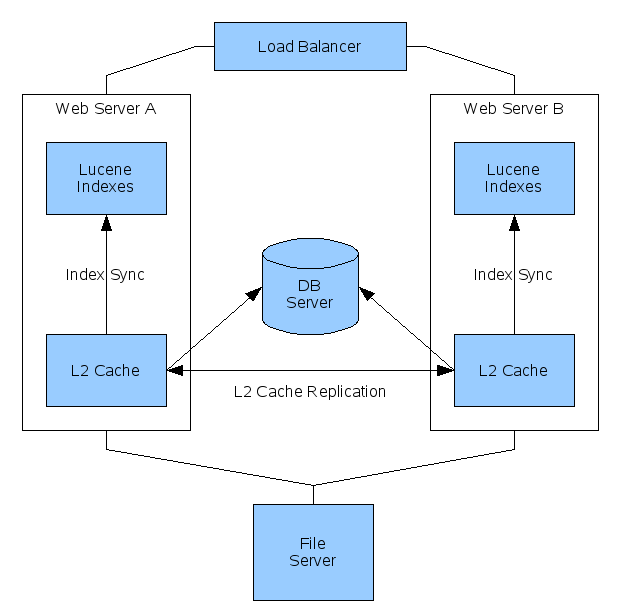
In this scenario, we have a single repository database and filesystem (for the content store) and multiple web app servers accessing the content simultaneously. This configuration does not guard against repository filesystem or database failure, but allows multiple web servers to share the web load, and provides redundancy in case of a web server failure. Each web server has local indexes (on the local filesystem).
For this example we will utilize a hardware load balancer to balance the web requests among multiple web servers. The load balancer must support 'sticky' sessions so that each client always connects to the same server during the session. The filesystem and database will reside on separate servers, which allows us to use alternative means for filesystem and database replication. The configuration in this case will consist of L2 Cache replication and index synchronization.
L2 Cache Replication
We will use EHCache replication to update every cache in the cluster with changes from each server. This is accomplished by overriding the default EHCache configuration in
<ehcache>
<diskStore
path='java.io.tmpdir'/>
<cacheManagerPeerProviderFactory
class='net.sf.ehcache.distribution.RMICacheManagerPeerProviderFactory'
properties='peerDiscovery=automatic,
multicastGroupAddress=230.0.0.1,
multicastGroupPort=4446'/>
<cacheManagerPeerListenerFactory
class='net.sf.ehcache.distribution.RMICacheManagerPeerListenerFactory'
properties='port=40001, socketTimeoutMillis=2000'/>
...
</ehcache>
Lucene Index Synchronization
Version 1.4.0 to 1.4.4
The Lucene indexes are updated from the L2 cache by the index recovery component. This is scheduled through the Alfresco Quartz scheduler, and is turned off by default. Start with the <extConfigRoot>/alfresco/extension/index-tracking-context.xml.sample and modify it to run the indexRecoveryComponent every 10 seconds.
<extConfigRoot>/alfresco/extension/index-tracking-context.xml
<bean id='indexTrackerTrigger' class='org.alfresco.util.CronTriggerBean'>
<property name='jobDetail'>
<bean class='org.springframework.scheduling.quartz.JobDetailBean'>
<property name='jobClass'>
<value>org.alfresco.repo.node.index.IndexRecoveryJob</value>
</property>
<property name='jobDataAsMap'>
<map>
<entry key='indexRecoveryComponent'>
<ref bean='indexTrackerComponent' />
</entry>
</map>
</property>
</bean>
</property>
<property name='scheduler'>
<ref bean='schedulerFactory' />
</property>
<property name='cronExpression'>
<value>0,10,20,30,40,50 * * * * ?</value>
</property>
</bean>
<bean
id='indexTrackerComponent'
class='org.alfresco.repo.node.index.IndexRemoteTransactionTracker'
parent='indexRecoveryComponentBase'>
<property name='remoteOnly'>
<value>true</value>
</property>
</bean>
Version 1.4.5, 2.1.1 and later
The above configuration has been pulled into internal context files. Properties changing the reindex behaviour are defined in the general <conf>/alfresco/repository.properties.
<ext-conf>/alfresco/extension/custom-repository.properties.
# Set the frequency with which the index tracking is triggered.
# By default, this is effectively never, but can be modified as required.
# Examples:
# Once every five seconds: 0/5 * * * * ?
# Once every two seconds : 0/2 * * * * ?
# See http://quartz.sourceforge.net/javadoc/org/quartz/CronTrigger.html
index.tracking.cronExpression=? ? ? ? ? ? 2099
index.tracking.adm.cronExpression=${index.tracking.cronExpression}
index.tracking.avm.cronExpression=${index.tracking.cronExpression}
# Other properties.
index.tracking.maxTxnDurationMinutes=60
index.tracking.reindexLagMs=1000
index.tracking.maxRecordSetSize=1000
The triggers for ADM (document management) and AVM (web content management, where applicable) index tracking are combined into one property for simplicity. These can be set separately, if required. The following properties should typically be modified in the clustered environment:
<ext-conf>/alfresco/extension/custom-repository.properties:
index.tracking.cronExpression=0/5 * * * * ?
index.recovery.mode=AUTO
Setting the recovery mode to AUTO will ensure that the indexes are fully recovered if missing or corrupt, and will top the indexes up during bootstrap in the case where the indexes are out of date. This happens frequently when a server node is introduced to the cluster. AUTO will ensure that backup, stale or no indexes can be used for the server.
NOTE: The index tracking relies heavily on the approximate commit time of transactions. This means that machines in a cluster need to be time-synchronized, the more accurately the better. The default configuration only triggers tracking every 5 seconds and enforces a minimum age of transaction of 1 second. This is controlled by the property index.tracking.reindexLagMsFor example, if the clocks of the machines in the cluster can only be guaranteed to within 5 seconds, then the tracking properties might look like this:
<ext-conf>/alfresco/extension/custom-repository.properties:
index.tracking.cronExpression=0/5 * * * * ?
index.recovery.mode=AUTO
index.tracking.reindexLagMs=10000
Clustered Login Credentials
This is now the default configuration in the sample as of V2.1.0E
Scenario
- Single, shared content store
- Sticky client sessions with login credentials failover
It is possible to replicate the session authentication tokens around the cluster so that the failover scenario doesn't require the client to login when switching to an alternative server. This doesn't replicate the client session, so 'sticky' sessions must still be active.
L2 Cache Replication
Active the extension sample ehcache-custom.xml.sample.cluster, but force the cache of authentication tickets to replicate via copy throughout the cluster:
ehcache-custom.xml
...
<cache
name='org.alfresco.cache.ticketsCache'
maxElementsInMemory='1000'
eternal='true'
overflowToDisk='true'>
<cacheEventListenerFactory
class='net.sf.ehcache.distribution.RMICacheReplicatorFactory'
properties='replicatePuts = true,
replicateUpdates = true,
replicateRemovals = true,
replicateUpdatesViaCopy = true,
replicateAsynchronously = false'/>
</cache>
...
</ehcache>
Local and Shared Content Stores
{kind=link}
Scenario
- Local content store replicated to shared store
Read the Content Store Configuration as an introduction.
This scenario extends the previous examples by showing how to replicate the content stores to have a content store local to each machine that replicates data to and from a shared location. This may be required if there is high latency when communicating with the shared device, if the shared device doesn't support fast random access read/write file access.
Content Replication
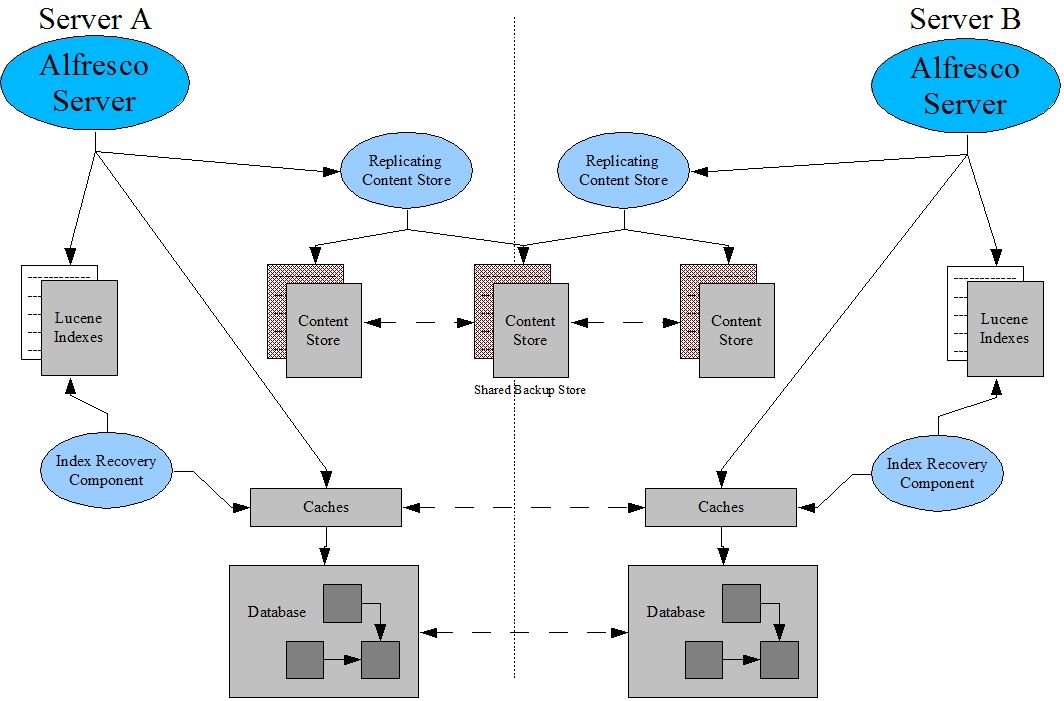
Assume that both Server A and Server B (and all servers in the cluster) store their content locally in /var/alfresco/content-store. The Shared Backup Store is visible to all servers as /share/alfresco/content-store. The following configuration override must be applied to all servers:
<ext-config>/alfresco/extension/replicating-content-services-context.sample:
<bean id='localDriveContentStore' class='org.alfresco.repo.content.filestore.FileContentStore'>
<constructor-arg>
<value>/var/alfresco/content-store</value>
</constructor-arg>
</bean>
<bean id='networkContentStore' class='org.alfresco.repo.content.filestore.FileContentStore'>
<constructor-arg>
<value>/share/alfresco/content-store</value>
</constructor-arg>
</bean>
<bean id='fileContentStore' class='org.alfresco.repo.content.replication.ReplicatingContentStore' >
<property name='primaryStore'>
<ref bean='localDriveContentStore' />
</property>
<property name='secondaryStores'>
<list>
<ref bean='networkContentStore' />
</list>
</property>
<property name='inbound'>
<value>true</value>
</property>
<property name='outbound'>
<value>true</value>
</property>
<property name='retryingTransactionHelper'>
<ref bean='retryingTransactionHelper'/>
</property>
</bean>
Read-only Clustered Server
Scenario
- Some servers are read-only
It is possible to bring a server up as part of the cluster, but force all transactions to be read-only. This effectively prevents any database writes.
Custom Repository Properties
<ext-config>/alfresco/extension/custom-repository.properties:
# the properties below should change in tandem
server.transaction.mode.default=PROPAGATION_REQUIRED, readOnly
server.transaction.allow-writes=false
#server.transaction.mode.default=PROPAGATION_REQUIRED
#server.transaction.allow-writes=true
Verifying the Cluster
This section addresses the steps required to start the clustered servers and test the clustering after the the necessary configuration changes have been made to the servers.
Installing and Upgrading on a Cluster
Clean Installation
- Start Alfresco on one of the clustered machines and ensure that the bootstrap process proceeds normally.
- Test the system's basic functionality:
- Login as different users
- Access some content
- Perform a search
- Modify some properties
- Login as different users
Upgrades
- Upgrade the WAR and config for all machines in the cluster.
- Start Alfresco on one of the clustered machines and ensure that the upgrade proceeds normally.
- Test the system's basic functionality.
- Start each machine in the cluster one
Testing the Cluster
There are a set of steps that can be done to verify that clustering is working for the various components involved. You will need direct web client access to each of the machines in the cluster. The operation is done on machine M1 and verified on the other machines Mx. The process can be switched around with any machine being chosen as M1.
Cache Clustering
- M1: Login as admin.
- M1: Browse to the Guest Home space, locate the tutorial PDF document and view the document properties.
- Mx: Login as admin.
- Mx: Browse to the Guest Home space, locate the tutorial PDF document and view the document properties.
- M1: Modify the tutorial PDF's description field, adding 'abcdef'.
- M2: Refresh the document properties view of the tutorial PDF document.
- M2: The description field must have changed to include 'abcdef'.
Index Clustering
- ... Repeat Cache Clustering.
- M1: Perform an advanced search of the description field for 'abcdef' and verify that the tutorial document is returned.
- Mx: Search the description field for 'abcdef'. As long as enough time was left for the index tracking (10s or so), the document must show up in the search results.
Content Replication / Sharing
- M1: Add a text file to Guest Home containing 'abcdef'.
- M2: Perform a simple search for 'abcdef' and ensure that the new document is retrieved.
- Mx: Refresh the view of Guest Home and verify that the document is visible. This relies on index tracking, so it may take a few seconds for the document to be visible.
- Mx: Open the document and ensure that the correct text is visible.
- Mx: Perform a simple search for 'abcdef' and ensure that the new document is retrieved.
If It Isn't Working ...
The following log categories can be enabled to help track issues in the cluster.
- log4j.logger.net.sf.ehcache.distribution=DEBUG: Check that heartbeats are receieved from from live machines.
- log4j.logger.org.alfresco.repo.node.index.IndexTransactionTracker=DEBUG: Remote index tracking for ADM.
- log4j.logger.org.alfresco.repo.node.index.AVMRemoteSnapshotTracker=DEBUG: Remote index tracking for AVM.
If cache clustering isn't working, the EHCache website describes some common problems: EHCache Documentation. The remote debugger can be downloaded as part of the EHCache distribution files and executed:
> java -jar ehcache-1.3.0-remote-debugger.jar
Command line to list caches to monitor: java -jar ehcache-remote-debugger.jar path_to_ehcache.xml
Command line to monitor a specific cache: java -jar ehcache-remote-debugger.jar path_to_ehcache.xml cacheName
Back to Server Administration Guide
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Hub Docs
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco Community Edition 201911 GA Release Notes
- Alfresco Community Edition 201910 EA Release Notes
- Deconstructing SOLR Indexes
- Alfresco Community Edition 201901 GA Release Notes
- Alfresco Community Edition 201808 EA file list
- php_upload.docx
- Alfresco Community Edition 201808 EA Release Notes
- Alfresco_6.0_docker deployment.pdf
- Alfresco Community Edition 201806 GA file list
- alfresco.log
- Alfresco Addons *Incomplete list*
- Alfresco Community Edition 201806 GA Release Notes
- AGS Benchmark Driver Documentation
- Default memory allocation issue in Alfresco CE 201...
- Alfresco Community Edition 201804 EA file list
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.