
High Availability On Linux
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Hub Docs
- :
- High Availability On Linux
High Availability On Linux
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
6 Jun 2015
0:40 AM
Obsolete Pages{{Obsolete}}
The official documentation is at: http://docs.alfresco.com
{{Partner Info
| companyName=Rivet Logic
| companyWebsite=http://www.rivetlogic.com
| companyLogo=RL_logo.jpg
| companyDescription=Artisans of open source.
| contactEmail=info at rivetlogic.com
}}
Table of Contents
- 1 Overview
- 2 Environment
- 3 Deployment Instructions
- 3.1 Initial Set up
- 3.2 Deploying Alfresco
- 3.2.1.3 Verifying the Cluster
- 3.2.1.3.1 Installing and Upgrading on a Cluster
- 3.2.1.3.1.1 Clean Installation
- 3.2.1.3.1.2 Upgrades
- 3.2.1.3.2 Testing the Cluster
- 3.2.1.3.2.1 Cache Clustering
- 3.2.1.3.2.2 Index Clustering
- 3.2.1.3.2.3 Content Replication / Sharing
- 3.2.1.3.3 If It Isn't Working...
- 3.2.1.4 CIFS & FTP
Overview
This document details the steps required to deploy the Alfresco Enterprise Content Management application in Linux. The deployment supports high availability and is thus considered an Alfresco cluster.
Environment
For the purposes of this document the Alfresco deployment is comprised of two servers running RedHat Ent Linux. The Alfresco applications are deployed in Tomcat 5 and use a PostgreSQL database. The Applications will be fronted by a load balancer that will distribute the user requests equally among the two Alfresco servers.
The version of Alfresco that these instructions are written for is 2.1.1 Enterprise.
Deployment Instructions
Initial Set up
To install Alfresco in Linux a few things must be done prior to unzipping the Alfresco bundle. You can think of the following as steps to set up the environment in preparation for the Alfresco application. These steps detail what needs to happen on both servers in the Alfresco cluster.
- Login as root
- Create /opt/alfresco2.1.1
- This is the directory that will hold the entire Alfresco deployment
- Create a link that points to the above directory and call it alfresco
- The link should look like so:
/opt/alfresco2.1.1
- The purpose of creating this link is to allow for the deployment of more than one version of the Alfresco application on the same server and have the ability to switch between them by simply pointing the soft link to the appropriate Alfresco version. That way the start up scripts do not need to touched on application upgrades.
- Create a user for the Alfresco application (we'll call this user alfresco but the user can be given any name)
- Create a group for the Alfresco user (we'll call this group alfresco but the group can be given any name)
- Make the alfresco user the owner of the alfresco2.1.1 directory tree
- The command to do this is:
chmod -R alfresco:alfresco /opt/alfresco2.1.1This will jail the Alfresco application into its folder and protect the server from any application malfunction. This is a general best practice to use with all 3rd party applications.
Deploying Alfresco
The next step would be to deploy the alfresco application. This is done by simply uncompressing the Alfresco bundle to /opt/alfresco like so:
cp alfresco-enterprise-tomcat-2.1.1.tar /opt/alfresco
cd /opt/alfresco
tar -xzvf alfresco-enterprise-tomcat-2.1.1.tar
Configuration
After the bundle is uncompressed a number of files will need to be modified in order to configure Alfresco to work as intended within the target environment.
Database & Content Store configuration
Since Alfresco is a Spring/Hibernate application it is obvious that one of the first things one must do is make the appropriate configurations required to point Alfresco to the appropriate database. This is done by creating a file called /opt/alfresco/tomcat/shared/classes/alfresco/extension/custom-repository-context.xml. Add the following to this file:
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE beans PUBLIC '-//SPRING//DTD BEAN//EN' 'http://www.springframework.org/dtd/spring-beans.dtd'>
<!--
This shows the common minimum configuration overrides.
By default, the content and indexes are located at a relative location, which should only
be used when doing a quick preview of the Alfresco server.
-->
<beans>
<!-- overriding to point to custom properties -->
<bean id='repository-properties' class='org.springframework.beans.factory.config.PropertyPlaceholderConfigurer'>
<property name='ignoreUnresolvablePlaceholders'>
<value>true</value>
</property>
<property name='locations'>
<list>
<value>classpath:alfresco/repository.properties</value>
<value>classpath:alfresco/version.properties</value>
<value>classpath:alfresco/domain/transaction.properties</value>
<!-- Override basic repository properties -->
<value>classpath:alfresco/extension/custom-repository.properties</value>
</list>
</property>
</bean>
<bean id='hibernateConfigProperties' 'org.springframework.beans.factory.config.PropertiesFactoryBean'>
<property name='locations'>
<list>
<value>classpath:alfresco/domain/hibernate-cfg.properties</value>
<!-- Override hibernate dialect -->
<value>classpath:alfresco/extension/custom-hibernate-dialect.properties</value>
</list>
</property>
</bean>
<bean id='authorityService' class='org.alfresco.repo.security.authority.AuthorityServiceImpl'>
<property name='authenticationComponent'>
<ref bean='authenticationComponent' />
</property>
<property name='personService'>
<ref bean='personService' />
</property>
<property name='nodeService'>
<ref bean='nodeService' />
</property>
<property name='authorityDAO'>
<ref bean='authorityDAO' />
</property>
<property name='permissionServiceSPI'>
<ref bean='permissionServiceImpl' />
</property>
<property name='adminUsers'>
<set>
<value>admin</value>
<value>administrator</value>
</set>
</property>
</bean>
</beans>
Notice the file classpath:alfresco/extension/custom-repository.properties above. That file needs to be created in the same location to override Alfresco's default database configuration to use PostgreSQL. The file should look like so:
###############################
## Common Alfresco Properties #
###############################
#
# Sample custom content and index data location
#
dir.root=/nas/alf_data/2.1.1/content
dir.indexes=/srv/alf_data/2.1.1/index
#
# Sample database connection properties
#
db.username=alfresco
db.password=alfresco
#
# PostgreSQL connection (requires postgresql-8.2-504.jdbc3.jar or equivalent)
#
db.driver=org.postgresql.Driver
db.url=jdbc:postgresql://localhost:5432/alfresco
The items above should be edited to match your environment. The following briefly describes each item:
| dir.root | Points to the full path of the directory that will hold the shared Alfresco content on the file system (this location is shared by both Alfresco servers in the cluster) |
| dir.indexes | Points to the full path of the directory that will hold the server's lucene index files. Note that each server in the Alfresco cluster needs to have its own local copy of the indexes. |
| db.url | The JDBC url pointing to the PostgreSQL database. |
| db.username | The username to login to the PostgreSQL database. |
| db.password | The password associated with the username above. |
The next file to create would be custom-hibernate-dialect.properties. That file is specific to Hibernate and instructs it to use the appropriate PostgreSQL dialect while executing database commands. The file should look like so:
#
# Sample Hibernate configuration for changing Database dialect
# For a full list: http://www.hibernate.org/hib_docs/v3/reference/en/html_single/#configuration-optional-dialects\\
#
# PostgreSQL dialect
#
hibernate.dialect=org.hibernate.dialect.PostgreSQLDialect
hibernate.query.substitutions=true TRUE, false FALSE
The Hibernate PostgreSQL dialect is set as illustrated above.
JDBC Library
In order for Hibernate to communicate successfully with the database the appropriate library file must be copied to the shared classpath for libraries. In this case, since we are using Tomcat 5, that path would be /opt/alfresco/tomcat/common/lib. And since we are using PostgreSQL, the library file to copy to that location would have to be compatible with the version of the PostgreSQL database being used. This would be a good time to ask the DBA for that file. But just as a reference, the file will have a name close to postgresql-8.2-504.jdbc3.jar.
Cluster specific configuration
It is important to note that the Alfresco cluster is designed as illustrated in the following diagram:
AlfrescoHA.png
{kind=link}
L2 Cache replication
The Level 2 cache provides out-of-transaction caching of JAVA objects inside the Alfresco system. Alfresco only provides support for EHCache. This document describes the synchronization of EHCache across clusters. Using EHCache does not restrict the Alfresco system to any particular application server, so it is completely portable.
We will use EHCache replication to update every cache in the cluster with changes from each server. This is accomplished by overriding the default EHCache configuration in /opt/alfresco/tomcat/shared/classes/alfresco/extension/ehcache-custom.xml. Since the complete configuration is given in the sample extension file ehcache-custom.xml.sample.cluster, copy that file to the new name ehcache-custom.xml and verify that the first section looks like so:
<ehcache>
<diskStore path='java.io.tmpdir'/>
<cacheManagerPeerProviderFactory class='net.sf.ehcache.distribution.RMICacheManagerPeerProviderFactory'
properties='peerDiscovery=automatic, multicastGroupAddress=230.0.0.1, multicastGroupPort=4446'/>
<cacheManagerPeerListenerFactory 'net.sf.ehcache.distribution.RMICacheManagerPeerListenerFactory' properties='port=40001, socketTimeoutMillis=2000'/>
...
</ehcache>
Note that the IP address and port in red comprise the multicast IP address and port used by all nodes in the Alfresco cluster. In other words each node in the Alfresco cluster must have an exact copy of this file.
Verifying the Cluster
This section addresses the steps required to start the clustered servers and test the clustering after the necessary configuration changes have been made to the servers.
Installing and Upgrading on a Cluster
Clean Installation
- Start Alfresco on one of the clustered machines and ensure that the bootstrap process proceeds normally.
- Test the system's basic functionality:
- Login as different users
- Access some content
- Perform a search
- Modify some properties
Upgrades
- Upgrade the WAR and config for all machines in the cluster
- Start Alfresco on one of the clustered machines and ensure that the upgrade proceeds normally
- Test the system's basic functionality
- Start each machine in the cluster one at a time
Testing the Cluster
There are a set of steps that can be done to verify that clustering is working for the various components involved. You will need direct web client access to each of the machines in the cluster. The operation is done on machine M1 and verified on the other machines Mx. The process can be switched around with any machine being chosen as M1.
Cache Clustering
- M1: Login as admin.
- M1: Browse to the Guest Home space, locate the tutorial PDF document and view the document properties.
- Mx: Login as admin.
- Mx: Browse to the Guest Home space, locate the tutorial PDF document and view the document properties.
- M1: Modify the tutorial PDF's description field, adding 'abcdef'.
- M2: Refresh the document properties view of the tutorial PDF document.
- M2: The description field must have changed to include 'abcdef'.
Index Clustering
- ... Repeat Cache Clustering.
- M1: Perform an advanced search of the description field for 'abcdef' and verify that the tutorial document is returned.
- Mx: Search the description field for 'abcdef'. As long as enough time was left for the index tracking (10s or so), the document must show up in the search results.
Content Replication / Sharing
- M1: Add a text file to Guest Home containing 'abcdef'.
- M2: Perform a simple search for 'abcdef' and ensure that the new document is retrieved.
- Mx: Refresh the view of Guest Home and verify that the document is visible. This relies on index tracking, so it may take a few seconds for the document to be visible.
- Mx: Open the document and ensure that the correct text is visible.
- Mx: Perform a simple search for 'abcdef' and ensure that the new document is retrieved.
If It Isn't Working...
The following log categories can be enabled to help track issues in the cluster.
log4j.logger.net.sf.ehcache.distribution=DEBUG: Check that heartbeats are received from live machines.
log4j.logger.org.alfresco.repo.node.index.IndexTransactionTracker=DEBUG: Remote index tracking for ADM.
log4j.logger.org.alfresco.repo.node.index.AVMRemoteSnapshotTracker=DEBUG: Remote index tracking for AVM.
If cache clustering isn't working, the EHCache website describes some common problems: EHCache Documentation. The remote debugger can be downloaded as part of the EHCache distribution files and executed:
> java -jar ehcache-1.3.0-remote-debugger.jar
Command line to list caches to monitor: java -jar ehcache-remote-debugger.jar path_to_ehcache.xml
Command line to monitor a specific cache: java -jar ehcache-remote-debugger.jar path_to_ehcache.xml cacheName
CIFS & FTP
Alfresco CIFS and FTP interfaces need to bind privileged ports on the server. There are two ways to make this possible. The first is to run Alfresco as a root user which is not recommended. The other would be to setup IP forwarding on each server in the cluster to map unprivileged ports to the privileged ones. The IP forwarding configuration is beyond the scope of this document, but as far as the necessary Alfresco configurations the following needs to be done:
- Create the file /opt/alfresco/tomcat/shared/classes/alfresco/extension/network-protocol-context.xml
- The contents of the file should look like so:
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE beans PUBLIC '-//SPRING//DTD BEAN//EN' 'http://www.springframework.org/dtd/spring-beans.dtd'>
<beans>
<!-- import further configurations -->
<bean id='fileServersConfigSource' class='org.alfresco.config.source.UrlConfigSource'>
<constructor-arg>
<list>
<!-- Load the standard config first -->
<value>classpath:alfresco/file-servers.xml</value>
<!-- Load any overrides after -->
<value>classpath:alfresco/extension/file-servers-custom.xml</value>
</list>
</constructor-arg>
</bean>
</beans>Note the file named 'file-servers-custom.xml'. This file should be created in /opt/alfresco/tomcat/shared/classes/alfresco/extension and should look like so:
<alfresco-config area='file-servers'>
<config evaluator='string-compare' condition='CIFS Server'>
<serverEnable enabled='true'/>
<host name='$\{localname\}A'/>
<comment>Alfresco CIFS Server</comment>
<!-- Set to the broadcast mask for the subnet -->
<broadcast>255.255.255.255</broadcast>
<!-- Use Java socket based NetBIOS over TCP/IP and native SMB on linux -->
<tcpipSMB platforms='linux,solaris,macosx'/>
<netBIOSSMB platforms='linux,solaris,macosx'/>
<!-- Can be mapped to non-privileged ports, then use firewall rules to forward
requests from the standard ports -->
<!--
<tcpipSMB port='1445' platforms='linux,solaris,macosx'/>
<netBIOSSMB sessionPort='1139' namePort='1137' datagramPort='1138' platforms='linux,solaris,macosx'/>
-->
<hostAnnounce interval='5'/>
<!-- Use Win32 NetBIOS interface on Windows -->
<Win32NetBIOS/>
<Win32Announce interval='5'/>
<sessionDebug flags='Negotiate,Socket'/>
</config>
<config evaluator='string-compare' condition='FTP Server'>
<serverEnable enabled='true'/>
<port>8021</port>
</config>
</alfresco-config>The ports above need to be mapped to the known NetBIOS and SMB ports like so:
1445 => 445 (TCP)
1139 => 139 (TCP + UDP)
1137 => 137 (TCP + UDP)
1138 => 138 (TCP + UDP)
Don't forget to set the broadcast IP to match your network. The FTP server configuration above is no different except that IP forwarding is probably not needed since FTP clients are easily configured with a port number for the destination FTP server.
Open Office
In order for Alfresco to perform some of its out-of-the-box mime-type transformations, Open Office needs to be running in headless mode and listening on port 8100. This is accomplished by installing Open Office (preferably 2.x) and running it using the following command:
/usr/X11R6/bin/Xvfb :1 -screen 0 800x600x16 -fbdir /usr/src &
soffice '-accept=socket,host=localhost,port=8100;urp;StarOffice.ServiceManager' '-env:UserInstallation=[file:////opt/alfresco/oouser]' -nologo
-headless -nofirststartwizard -nocrashrep -norestoreard -nocrashrep -norestore -display :1 &
Init scripts
In order for Alfresco to be automatically started on boot, a couple of init scripts need to be in place, one for Open Office and one for the Alfresco application.
Open Office init script
Location: /etc/init.d/ooffice
#!/bin/sh
#
# Startup script for Open Office 2.0 Healdess mode
#
# chkconfig: 345 90 14
# description: Open Office
# processname: soffice
# pidfile: /opt/openoffice.org2.3/program/soffice.pid
#
# User under which Open Office will run
OOFFICE_USER=alfresco
RETVAL=0
# start, debug, stop, and status functions
start() {
echo 'Starting OOffice...' su - $OOFFICE_USER -c '/opt/openoffice.org2.3/program/soffice '-accept=socket,host=localhost,port=8100;urp;StarOffice.ServiceManager'
'-env:UserInstallation=[file:////opt/alfresco/oouser]' -nologo -headless -nofirststartwizard -nocrashrep -norestoreard -nocrashrep -norestore > /dev/null 2> /dev/null' &
echo 'OOffice started'
}
stop() {
echo 'Stopping OOffice...'
su - $OOFFICE_USER -c 'pkill soffice'
echo 'OOffice stopped'
}
status() {
OOFFICE_PORT=`netstat -vatn | grep LISTEN | grep 8100 | wc -l`
if [ $OOFFICE_PORT -eq 0 ]; then
echo 'OOffice stopped'
else
echo 'OOffice running'
fi
}
case '$1' in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
status)
status
;;
*)
echo 'Usage: $0 {start|stop|restart|status}'
exit 1
esac
exit 0
Alfresco init script
Location: /etc/init.d/alfresco
#!/bin/sh
#
# Startup script for Alfresco
#
# chkconfig: 345 96 14
# description: Tomcat Servlet Engine
# processname: tomcat
# pidfile: /opt/alfresco/alfresco.pid
#
# User under which tomcat will run
TOMCAT_USER=alfresco
RETVAL=0
# start, debug, stop, and status functions
start() {
# Start Tomcat in normal mode
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
if [ $SHUTDOWN_PORT -ne 0 ]; then
echo 'Alfresco already started'
else
echo 'Starting alfresco...'
su - $TOMCAT_USER /opt/alfresco/alfresco.sh start
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
while [ $SHUTDOWN_PORT -eq 0 ]; do
sleep 1
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
done
RETVAL=$?
echo 'Alfresco started'
[ $RETVAL=0 ] && touch /opt/alfresco/lock/alfresco
fi
}
stop() {
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
if [ $SHUTDOWN_PORT \-eq 0 ]; then
echo 'Alfresco already stopped'
else
echo 'Stopping alfresco...'
su - $TOMCAT_USER /opt/alfresco/alfresco.sh stop
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
while [ $SHUTDOWN_PORT -ne 0 ]; do
sleep 1
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
done
RETVAL=$?
echo 'Alfresco stopped'
[ $RETVAL=0 ] && rm -f /opt/alfresco/lock/alfresco /opt/alfresco/alfresco.pid
fi
}
status() {
SHUTDOWN_PORT=`netstat -an|grep LISTEN|grep 8005|wc -l`
if [ $SHUTDOWN_PORT -eq 0 ]; then
echo 'Alfresco stopped'
else
echo 'Alfresco running'
fi
}
case '$1' in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
status)
status
;;
*)
echo 'Usage: $0 {start\|stop\|restart\|status}'
exit 1
esac
exit $RETVAL
Disaster Recovery
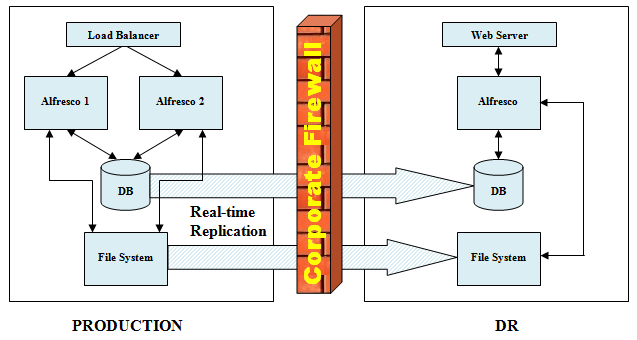
The idea here is to provide a remote site that is periodically synchronized with the production environment in case a natural or unforeseen disaster occurs that renders the production environment unusable.
Strategy
The proposed strategy is to replicate Alfresco file system content and database tables in real-time from production to DR (Disaster Recovery environment). When a disaster occurs, the DR Alfresco application would be launched and would feed off of the replicated data. When the production environment is ready for use, manual replication of Alfresco file system content and database tables would need to occur from DR to production. It is important to note here that bringing up the Alfresco cluster in production should be done one server at a time. The following diagram illustrates what the DR environment will look like relative to production:
{kind=link}
The items that need to be replicated in real-time are:
- Alfresco database
- Contents /nas/alf_data/2.1.1/content need to be replicated to the DR server at the same location
- Contents /srv/alf_data/2.1.1/index need to be replicated from Production to the DR server at the following location:
/srv/alf_data/2.1.1/index (this needs to be done for both servers, but the destination is the same)
Note: The indexes can be created at the DR server so replication of index files is not really necessary.
Failover
If everything is configured and is working as expected all that needs to be done is:
- Launch the Alfresco application on DR
- Point the application's URL to the web server running in DR
- Access Alfresco and login successfully
Failback
Failing back to Production from DR entails following these steps:
- Copy the contents of /nas/alf_data/2.1.1/content from DR to the Production server at the same location
- Copy the contents of /srv/alf_data/2.1.1/index from DR to the Production servers at the following locations
- /srv/alf_data/2.1.1/index on the first server
- /srv/alf_data/2.1.1/index on the second server
- Copy the Alfresco database from DR to Production
- Launch Alfresco on Server1 in Production
- Access Alfresco and login successfully
- Launch Alfresco on Server2 in Production
Appendix A
How to test Alfresco load balancing
When everything is configured as expected and as illustrated in the diagram above follow these steps:
- Start Alfresco on Server1
- Access Alfresco directly on Server1:8080
- Start Alfresco on Server2
- Access Alfresco directly on Server2:8080
- Access the load-balanced URL (usually on port 80)
- Browse the Alfresco folders
- Shut down Server1
- Access the load-balanced URL (The user might be asked to re-login which is normal. As long as the user does not get a page not found error then it's ok.)
- Browse the Alfresco folders
- Start Alfresco on Server1
- Shut down Server2
- Access the load-balanced URL (The user might be asked to re-login which is normal. As long as the user does not get a page not found error then it's ok.)
If the user does not experience any application down-time (e.g. no page found error) then the test is considered a success.
{kind=link}
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Hub Docs
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco Community Edition 201911 GA Release Notes
- Alfresco Community Edition 201910 EA Release Notes
- Deconstructing SOLR Indexes
- Alfresco Community Edition 201901 GA Release Notes
- Alfresco Community Edition 201808 EA file list
- php_upload.docx
- Alfresco Community Edition 201808 EA Release Notes
- Alfresco_6.0_docker deployment.pdf
- Alfresco Community Edition 201806 GA file list
- alfresco.log
- Alfresco Addons *Incomplete list*
- Alfresco Community Edition 201806 GA Release Notes
- AGS Benchmark Driver Documentation
- Default memory allocation issue in Alfresco CE 201...
- Alfresco Community Edition 201804 EA file list
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.