Obsolete Pages{{Obsolete}}
The official documentation is at: http://docs.alfresco.com
Content Modeling
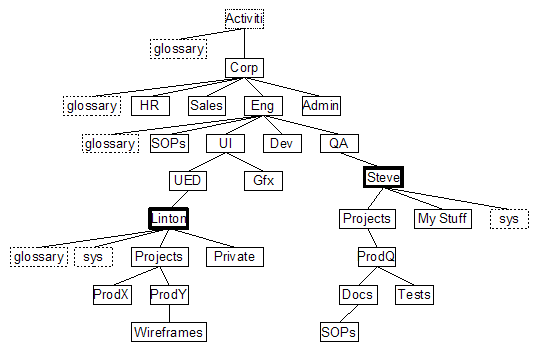
Meta-data about content will be defined in Glossaries. A Glossary is a type of Space (probably hidden, definitely protected) that contains the different kinds of meta-data defined at that level in the repository structure. There may be any number of Glossaries and they are created explicitly by the user (with the exception of a Home Space - it is always expected to have a Glossary inside). When looking for definitions to use, the system will use all Glossaries linked to the ancestors of the current location, overriding if permitted (option on user or site?).
Glossaries in a repository
A Glossary will contain Spaces for Categories and Capabilities. These may also be hierarchical and override definitions in Glossaries 'higher' in the ancestors.
A Glossary
Content Types
Rather than take the standard approach to defining strict information types, like in object-oriented programming, it is more natural to use the idea of stereotypes. The idea is similar to a type, but doesn't have the same connotations of subtypes and inheritance. Instead, a stereotype groups together a number of aspects or facets that typify it, but doesn't force an instance to fully meet all the expectations or not to have additional facets. It is also possible for an instance to change stereotypes.
A stereotype can be considered just as a container - a folder with additional definitions that need to be applied to everything contained within it. For example, a Space could declare that everything within it was versionable and should have a given extra set of properties.
There will still be a need for the concept of base content types, but it is unlikely that these will grow into larger type hierarchies. Base types will be core structural definitions, such as File, Folder, ForumEntry, Bug and so on. However, it isn't expected that a user, even an advanced one, would extend the core types - that would be a task defined and loaded via an XML format by system administration.
Classifications
Content Capabilities
Back to Application Requirements

{kind=link}
{kind=link}
{kind=link}
{kind=link}