
JackRabbit
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Hub Docs
- :
- JackRabbit
JackRabbit
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
6 Jun 2015
0:40 AM
Obsolete Pages{{Obsolete}}
The official documentation is at: http://docs.alfresco.com
Code Review
Andy's Comments
- No version control
- Persistence is not synchronised and will have threading issues
- Waiting to update to latest commons-id
- Name spaces not yet fixed (although it seems so in JSR)
- UUID generation and collision at import
- Creation of protected nodes is not implemented
- System properties are in document XML
- XML serialization will probably produce invalid XML (name encoding)
- Internal use of a safe path separator (uses tab)
- path indexing of 0 and 1 equivalent - XPath and JSR 170 disagree
- Like operation does not understand name spaces.
- Does the rest – not date ?? (which I do not understand …)
- String escaping for like is incomplete in the query languages
- Comments to add performance caching in search fts search and queries
- Uses lucene for fts
- Not sure if they have workspaces> (There is no system workspace and noy dynamic workspace. I think there is just one * workspace) - Could support this in subversion style
- There can be multiple instantiations pointing at the same repository which will cause havoc.
- Does authentication and authorization work – looks very simple …
- Version and other special nodes (lock) are not treated correctly in copy
- Restore is not implemented
- The tot says implement versioning!
- There are references to use of attic ala cvs
- Should use mod count and not time stamp for versioning
- There is no efficient hierarchy index – high lighted for performance
- Create node does not do mandatory type??
- Property serialisation is simple
- There is no config for blob storage – fixed in a known position
- The presence of repeated siblings seems to have issues
- There is no locking support
- File system lock is not atomic
Dave's Impression
I've taken a look at most of the JackRabbit source code - version 0.16.2. I have mixed feelings about this stuff.
Negative:
My overall impression is that it seems remarkably over complex, given the nature of the JCR interfaces. Note: Complex != sophisticated, just wrong.
Pretty much, they've implemented a complete content repository from the ground up - the only library dependencies I could find are Lucene and Jakarta Commons Collections. Perhaps this is the way for Reference Implementations.
The complexity comes from the fact that there's an awful lot of code that isn't really JCR related. I'm surprised by the amount of code that effectively provides (in-memory) cache management for node and property state. This might not be so bad, but I can't see how it actually works in a multi-user environment. How do the caches get refreshed? How are they all synched? Why are there basically hash maps upon hash maps upon hash maps of cache?
In the bug tracking system, the following comment may back this up - 'i must admit that i took no care about multihtreading until now. but of course i will do it now.' - a comment from the guy who wrote the versioning piece.
When you look at the code, you get the Slide v1.0 feeling. There are going to be bugs due to the amount of in-memory data structures that need to be kept just right - in a multi-threaded context. It's not the sort of thing that's easily fixed - there will be a Slide 3.0 equivalent when a re-design of the architecture is considered.
Given all this caching, hierarchy related processing performance will still suffer. There's no indexing as far as I can see.
Currently, the persistent store is the file system. This is fine, but again, I wonder about multi-user support. I can't see any form of locking or atomic support. Properties seem to be stored separately from Nodes - so more file access is required for each property (although, this looks like it will be fixed).
DM_SYSOBJECT again - except its called NodeImpl.java this time. Yep, the size of this file dwarfs everything else.
As Andy has pointed out, there are numerous holes and inconsistencies - I expect these will get fixed as time goes by.
Positive:
It does seem to provide most of the features of the JCR spec - Typing, Workspaces, Versioning, Search, Events etc. Bear in mind, on top of the questionable innards.
Workspaces are kept simple; they're just folders in their own right. Versioning, again, is just another folder of files. The Type System again is very simple - an XML file provides the type definitions which are read into in-memory structures and that's about it.
I believe our proposed approach of tying a Workspace to a simple DB schema (without versioning) still holds.
Their TODO List:
- locking
- access control (jaas)
- use jdbc as an alternative to virtual filesystem persistence layer
- use an alternative journaling store as (transactional) persistence layer
- provide clean abstraction for persistence grouping (nodes & properties that should be stored/loaded together in the persistence layer); (e.g. properties are stored within .node.xml)
- need a more efficient way to persistently remove state of items in transient attic (nodes in transient attic are orphaned, i.e. they are disconnected from the hierarchy and can thus not be easily identified on Node#save): => need a hierarchical cache index for items in the transient attic (see TransientItemStateManager), sparse tree index?; this index needs to be maintained/updated on every transient & persistent hierarchy operation (move, remove, copy)
- HierarchyManager: cache Path objects (key: ItemId, value: Path[]); update cache on hierarchy changes (move, hardlink, remove, etc)
- inline @todo comments: resolve/implement
- javaDoc, javaDoc, javaDoc
- logging: use commons logging instead of log4j
- logging: remove unnecessary output, check log categories/verbosity, use 'debug' whenever possible
What do we do with JackRabbit?
We could:
- Use it as our basic Repository capability - build our stuff around it
- Build our own Repository capability and use JackRabbit where possible to provide a JSR-170 facade
- Not use it at all
Option 1 might be viable if it's a stepping stone to building a community quickly with the intention of replacing it.
But, my preference is option 2. We'd probably gut JackRabbit anyway (not very nice!!) to cater for native db implementation and subversion type capability and also to fix reliability issues. However, it would give a head-start to providing a facade to our own stuff e.g. Type Model, Query etc.
Magnolia
Magnolia is supposedly housed on JackRabbit. My brief scan of Magnolia did not reveal an updated or patched version of JackRabbit, so I'm a little unsure how Magnolia can work properly (reliably) in a mult-user environment.
I'm going to check Magnolia again - the source and our installation here to see if it's using JackRabbit.
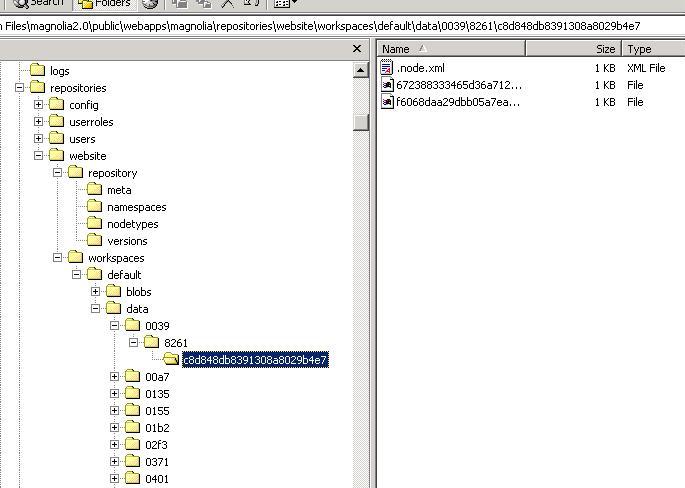
Update:This is our installation of Magnolia. Yes, it does look to be using JackRabbit. You can see the Repository subfolders, in particular the workspacs/default folder. Node id's are converted to folder structures.
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Hub Docs
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco Community Edition 201911 GA Release Notes
- Alfresco Community Edition 201910 EA Release Notes
- Deconstructing SOLR Indexes
- Alfresco Community Edition 201901 GA Release Notes
- Alfresco Community Edition 201808 EA file list
- php_upload.docx
- Alfresco Community Edition 201808 EA Release Notes
- Alfresco_6.0_docker deployment.pdf
- Alfresco Community Edition 201806 GA file list
- alfresco.log
- Alfresco Addons *Incomplete list*
- Alfresco Community Edition 201806 GA Release Notes
- AGS Benchmark Driver Documentation
- Default memory allocation issue in Alfresco CE 201...
- Alfresco Community Edition 201804 EA file list
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.