
Link Management
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- ACS - Hub Docs
- :
- Link Management
Link Management
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
6 Jun 2015
0:40 AM
Obsolete Pages{{Obsolete}}
The official documentation is at: http://docs.alfresco.com
OBSOLETE PAGE
Table of Contents
Link Management
Overview
The primary objective of link management is to call attention to hyperlinks that don't work. There are many reasons why a URL might fail. For example: the resource being referenced doesn't exist, the certs on an HTTPS connection is stale or invalid, firewall issues, timeouts, etc. Minimizing a website's 'links to nowhere' requires some up-front design work, as well as regular maintenance and monitoring. Pointing to a resource using a URL is more subtle than it might appear at first because:
- Websites often employ multiple schemes for classifying/naming resource.
- Evaluation context can alter how a link binds to a resource (e.g.: via cookies, referrer, etc.)
- Links can be unintentionally ambiguous or overly specific
Therefore, the tasks of URL design and maintenance within a website are intertwined. The design and evaluation context of a link implies things about what website changes will cause it to break, point at something else, or remain the same. It is normal to have broken links during website development, and important to allow developers to create them temporarily. Without this ability, reorganizing a collection of interdependent assets can become needlessly painful, and can even lead to 'deadlock' situations. Further, because websites can generate links on the fly based on any computation, it is theoretically impossible to check 'all the links'; there's simply no way to tell that every link the site can generate has been generated, or even if the set is finite! For these reasons, the goal of link management is to find certain well-defined problems (not all of them), and to report them (not prevent them).
Alfresco includes several features that identify a wide range of problems at submit time, during reviews, within workareas (on demand), and prior to publishing a website. Unlike a simple file parser utility, Alfresco's link validation service makes requests for web pages to a server; thus links that are created dynamically within these pages can also be tested, along with whatever content filters the website/webapp has in place. This approach is much more thorough than a simple 'flat file parser', as it simulates what a normal user would experience if they were to browse the site.
Because websites can be very large, may contain a substantial number of JSPs (each of which must be compiled before running), and may reference external sites that are slow to respond, even an incomplete validation can be cpu, memory, bandwidth, and time-intensive. Various configuration parameters allow for some degree of tuning, but if there is some feature you'd like to see that isn't currently in place, please write to us! As always, your feedback is welcome.
Semantic Issues
URI, URL,URN
W3C defined a few different kinds of 'references': URI, URL, and URN. Before talking about 'links', it's probably worth reading T. Berners-Lee's formal definition of these terms (see: [RFC3986] for more details):
A URI can be further classified as a locator, a name, or both. The term
'Uniform Resource Locator' (URL) refers to the subset of URIs that, in
addition to identifying a resource, provide a means of locating the resource
by describing its primary access mechanism (e.g., its network 'location').
The term 'Uniform Resource Name' (URN) has been used historically to refer
to both URIs under the 'urn' scheme [RFC2141], which are required to remain
globally unique and persistent even when the resource ceases to exist or
becomes unavailable, and to any other URI with the properties of a name.
An individual scheme does not have to be classified as being just one of
'name' or 'locator'. Instances of URIs from any given scheme may have the
characteristics of names or locators or both, often depending on the
persistence and care in the assignment of identifiers by the naming authority,
rather than on any quality of the scheme. Future specifications and related
documentation should use the general term 'URI' rather than the more restrictive
terms 'URL' and 'URN' [RFC3305].
The following are two example URIs and their component parts:
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/\_________/ \_________/ \__/
| | | | |
scheme authority path query fragment
| _____________________|__
/ \ / \
urn: example:animal:ferret:nose
RFC 2141 defines a syntax for URNs. URNs specifically designed to be used as globally unique identifiers. They are valid URIs. They look sort of like URLs you might type in a browser, but URNs are not designed to be clickable. They're just structured identifiers.
Currently, link validation in Alfresco concerns itself with 'http' and 'https' URLs, though sometimes the more general term URI is used interchangeably.
What are 'links' in link management?
There are different forms of 'link management' and different contexts in which it can be done. In web content management, 'links' are hyperlinks (arbitrary URIs). However, in a more general sense, items may be linked by rules, triggers, metadata associations, and so forth. 'Linkage' can be explicit or implicit, static or dynamic, direct, or indirect. Dependency rules among 'linked' items may themselves be static or dynamic (though static rules are typically easier to administer correctly), and their evaluation and/or enforcement may be optional, mandatory, or mandatory-but-manually-overridable. In some cases, dependency cycles are acceptable & expected (e.g.: hyperlinked pages), while in others they must be detected and flagged as errors (e.g.: 'Make'). The evaluation of a rule set with respect to a set of 'linked' items often involves the construction of transitive closures, and sometimes does so with an eye towards exploiting opportunities for semantic-preserving optimizations (rewriting, reordering, rescheduling, etc.), parallelism, and distributed computation.
What's being 'managed' in link management?
The 'management' part of 'link management' implies the ability to set priorities and make tradeoffs. For example, it's often important to sacrifice some amount of accuracy (or timeliness) in one part of the system in order to maximize overall throughput on the system level. In other situations (e.g.: QA testing), the highest priority is almost always ensuring correctness. Therefore, a system that claims to 'manage links' should allow its administrator to configure it to automate various task-specific managerial policies.
Link Semantics
Even if you constrain yourself to equating the term 'link' to mean 'arbitrary URI', a URI may be intended to denote a wide array of different things. For example:
- A named location
(whatever happens to be on *this* splash page) - A link to a specific version of an immutable asset
(an objid of a document within a DM system) - A link to an immutable asset within an immutable closure
(a permalink within a archived edition of a website) - A function callsite
(server-parsed wiki terms, explicit GET URIs)
The Problem Domain
There are a few 'core' problem domains that any comprehensive link management system must address. Each of them corresponds to an important use case; solving one does not address the needs arising in the others. They are:
- Link validation
- Link (re)generation
- Link (re)interpretation
NOTE: In the 2.1 release, Alfresco will only be concerned with link validation.
Link Validation
Detecting broken links before end users are subjected to them is one of the most primary functions of link management. The degree to which you can perform this task efficiently and reliably is the final 'gold standard' of a link management system.
Observations
- Staging has many files, but nearly all submits are small (<20 files).
- Tracking dependency info across all rename/delete ops is expensive.
- Staging dependencies need to be calculated via deltas for efficiency.
- Dependency delta info can be inferred from workflow file-level deltas
- Delta info can be merged with staging dependency/link info on update
- Delta-based systems must be robust to out-of-band constraint violations
- Snapshots don't represent the entire state of a website, due to external links
- Snapshot checking can be done asynchronously
Solution Approach
Dependency differences between a workarea and staging are calculated lazily at submit time, and possibly again at review & update time (though this can sometimes be optimized away). If staging dependencies can only be modified via wokflow-driven transactions, then the staging side of the workarea/staging comparison is coherent. If no files are modified in the users area during a submit operation, then the workarea side of the workarea/staging comparison is coherent too; thus, submit/review link checking can be efficient & coherent. The staging area may have changed between submit, review, and/or update time. Therefore, the update logic for the Staging dependency and link meta info needs to be calculated lazily during the update transaction, not during submit or review.
Here's a outline of the submit/update link checking algorithm:
- Save persistent dependency meta info in staging snapshots
- Create ephemeral meta info deltas based on workflow area at submit time.
- Merge (possibly recalculated) ephemeral WF delta at staging update time.
- Out-of-band violations are handled via snapshot-diffing background threads.
Implementation Details
The first thing to understand about link validation in Alfresco is that it operates on snapshots, not HEAD. The main reasons for this are to avoid the need to hold submit transactions open for lengthy periods of time, and to avoid 'referential skew' across checkins. Validating the links within a snapshot provides insulation from checkins that might occur while the validation process is still underway. When complete, the information collected might very well be stale with respect to what is now the 'latest snapshot', but at least it's self-consistent for a particular version.
The next thing to realize is that when a user is checking links in an author sandbox, it's important for this to be fairly quick (i.e.: quicker than validating the entire website). Because there may be arbitrarily many broken links in the staging area, it's also important to isolate those links that are specifically broken by changes in the author's sandbox from all other broken links. If this were not done, the report would quickly become useless. For these reasons, only the modified files in an author (or workflow) sandbox are checked directly; the system can infer what other links are broken by analyzing dependencies. If this were not done, deleting a single file would necessitate revalidating the links in all files, whether modified or not. This would violate the design goal of keeping link checking in author areas fairly quick & efficient.
Consider the following versions within the staging area of a web project:
- HEAD
- The latest snapshot
- The snapshot currently being validated
- The latest completely validated snapshot
Link validation is an inherently slow process for several reasons: external hyperlinks can traverse slow networks and point at servers that are unresponsive, internal links can require the compilation of a large number of JSPs, timeouts need to be generous to avoid falsely declaring a link to be 'dead', and so on.
Let's suppose the 'latest completely validated snapshot' version was X. Recall that it's important to do updates asynchronously because they can take a long time, and holding transactions open for lengthy periods in a multi-user environment is a very bad idea. Thus by the time we can begin to validate a new version, several checkins may have already occured since version X. Let's say we're up to version Y now (where Y may be >> X). If version Y becomes the version 'currently being validated', it's insulated from further checkins. Perhaps the staging area is all the way up to version Z (where Z may be >> Y) by the time version Y is completely validated.
When a user decides to validate the broken links in an author sandbox, the validation must be done relative to a snapshot in staging because it can be lengthy, and we wouldn't want to suspend checkins for all users just because someone wanted to validate the links in their own private sandbox. Thus validating author sandboxes against HEAD isn't a viable option because the transaction time would be too lengthy. Similarly, authors cannot validate against the 'latest snapshot' because this is constantly changing too, as others successfully checkin new content into staging. Therefore, the delta between an author area and staging is done for a fixed version of staging when it comes to validating links. Obviously, this 'fixed' version cannot be the one that is 'currently' being validated, because the data for this version isn't fully available yet; without a completely validated version to check against, it becomes impossible to infer which links are broken when a file in the author's area is deleted. Thus, author areas are validated against the 'latest completely validated snapshot' in staging, even though the virtualization server presents them against the backdrop of HEAD in staging.
Fortunately, the fact that the link validation of staging may 'lag' the latest snapshot is usually not a big problem; link checking for authors is intended as a fast way to find obvious problems, not as final QA for the website itself. For this, you should deploy a snapshot to a separate QA machine that can be stress-tested without interfering with the work of developers (and vice versa).
Typically, checkings involve a small number of files, so when the validation service is 'lagging', it's usually not lagging by very much. To call the author's attention to 'lag', the validation report includes a notice that states what the latest snapshot in staging is, and what version the author's content was validated against.
Link (Re)generation
Template-driven web have the advantage of being highly scalable at runtime, but they place a greater burden on the development-side. By maintaining dependency maps, and allowing the developer to recompile pages only when necessary, very high-performance 'pre-cooked' sites can be kept up to date in an efficient manner. For big sites, it's usually best for the bulk of the pages to be precompiled via a templating system that allows the majority of users to enter well-structured data only. This keeps the data in a form that allows it to be re-purposed by other data rendering engines, should the need arise to do structured queries on it, or have the data appear in other output formats (e.g.: .pdf, .doc, with rss feeds, etc.).
The ability to (re)generate links automatically is implied by the ability to (re)generate web pages (or any other asset) using a rule-driven system. It is critical for this system to allow the user to perform multiple actions that cause the artifacts it creates to become 'stale' without actually triggering any (re)generation rules; this allows a sequence of changes to be made interactively without doing a full rebuild. It is also sometimes useful to limit the required rebuild to stale files that already exist within a particular set of directories. Here's a list of actions that one might wish to apply contents of a virtual repository (e.g.: the author, workflow, or staging workarea of a sandbox):
- (Re)generate every stale asset
- (Re)generate every stale asset relative to a constrained set of dependencies (typically, modified files)
- Regenerate every stale asset within a set of directories
- Regenerate every stale asset within a set of directories relative to a constrained set of dependencies
It should also be possible for a 'stale' file to be detected during submit operations. The Alfresco GUI should strongly encourage users to rebuild such files, and make it easy to do so; however, it should also allow them to force the submission through anyway. Aside: an optional comment explaining why submission was forced might be helpful.
It is worth noting that while generation and/or regeneration are possible in (1) and (2), only regeneration can be relied upon in (3) and (4). Therefore, (3) and (4) should be considered 'advanced options' because a naive user might not realize that something that does not currently exist cannot be examined to see if it's 'stale'. However, an advanced user could take great advantage of (3) or (4) to do a lightweight assessment of a sweeping change. For example, If a footer with hyperlinks were compiled into every page in a website via templating (rather than being included as a server-side include), one might wish to try out the new 'look and feel' in a single directory before regenerating all affected pages in all directories.
Link (Re)interpretation
Some links are not links to files, but rather identifiers to some other system that fetch data via a level of indirection. For example, a link may fetch a page (or cause a page to be assembled on the fly) in a manner that involves relational queries & business logic. Automating the management of URIs that are created with different semantics implies preserving whatever semantics were intended. Thus, tools to handle changes in the dynamic resolution of links that involve some amount of logical indirection tend to be at specific to the framework in which the indirection itself takes place (e.g.: wikis, links to database-driven servlets bearing query string args, etc.).
Practical Considerations
It's important to realize that submit/review-time checking alone cannot catch all possible problems because depending on how and when submissions/reviews are done, a 'submission/review' and it's associated 'update' in staging can be quite far apart in time. If the reviewer rejects the submission, the update to staging won't occur at all. To compound the issues a bit more, when you've got many users and/or many reviewers, the relative ordering of submissions and their associated updates to staging aren't necessarily done in an order-preserving way because if we set a global transaction lock that preserved order across all submissions globally, one slow reviewer could bring the entire collaborative effort to a halt. This is plainly unacceptable. Any link is potentially dependent upon a huge number of assets via some webapp-specific logic involving an arbitrary number of levels of data-driven indirection.
Thus, even when each step is a well-behaved transaction a final pass is still required on the snapshot in the staging area you're considering deploying. In short, the 'harm reduction' that's feasible at submit/review time is not a replacement for pre-deployment QA testing. As odd as it may sound at first, it's also quite important to allow users to submit files that they already know contain broken links. There are several why this paradoxical-sounding feature is desirable, but in a nutshell, if you're too strict up-front, then users end up being backed into awkward situations for no good reason. Consider this:
- Alice is given an assignment to work on a page name X.
- X must link to file Y.
- Bob is given an assignment to work on a page name Y.
- Y must link file X.
- Neither file X nor file Y exist when Alice and Bob are given their assignments.
If Alice and Bob had to work around a system that was *always* strict about not allowing dead links in checkins, then they'd need to first submit a 'dummy' version of their file that violated the constraint 'must link to X|Y' (and they'd have to wait for the other person to do so prior to submitting their *real* file).
The thing to note here is that even with all the pain and end-user confusion that 'ultra strict' policy would inevitably generate, the final website would be no better off for it! Remember: you'll be doing *final* QA/linkchecking prior to deployment anyhow. Most of the time, Alice & Bob will rectify problems like this on their own (because they've seen the alerts), but if they fail to do so, you can catch their mistake in an automated way. The less Alice & Bob have to struggle with pointless rigidity, the more time they'll have to sort things out.
The details about how the GUI will look for 'submit time' and final pre-deployment 'QA' link checking is still in flux, but hopefully there's enough enough detail here to be useful.
Here are a few implementation-driven terms:
- 'submit time' - when files are copied from user's area to workflow area
- 'review time' - when the reviewer examines the submitted item(s)
- 'update time' - when files are copied from workflow area to staging area
There are a few different contexts where link checking is valuable. Different tradeoffs must be made to account for the what's possible/needed in each case; however, the core techniques used in each are very similar. Each type or 'checking context' adds value not obtained by the others:
Link checking context Constraint Enforcement Benefit
----------------------+---------------------------+-------------------------
Users's workarea | none (info only) | sanity check / devel.
Submittable workflow | relaxed via override op. | harm reduction
Submitted workflow | relaxed (info only) | review
Approved workflow | none (updates state) | compute staging delta
Staging Snapshot | sync strict | sanity check / light qa
Deployed Snapshot | sync strict | final QA
----------------------+---------------------------+-------------------------
User Interface
This section highlights the link management GUI added to the Web Client in the 2.1 release.
Features
The link management GUI allows the current state of the links in the web project to be checked, this can either be done in the staging sandbox or an author can run a check on their sandbox.
NOTE: The GUI was enhanced in the 2.1 Enterprise version so some of the screenshots below may be unfamiliar. All these changes have now been applied to the Community version and therefore available in a nightly build and the next release.
Check Links In Staging Sandbox
Links can be checked with the new 'Check Links' action in the staging sandbox as shown below.
{kind=link}
This will launch the link validation report showing the status of all links. Links are being continually checked in the background as checkins to the staging sandbox are executed. There is therefore the possibility that the report is slightly 'behind'. If this happens the link validation report will show a warning indicating how far 'behind' the results are in terms of snapshot version numbers, this is shown in the screenshot below.
Link_validation_report_behind.gif
{kind=link}
Check Links In Authors Sandbox
Links can also be checked within an authors sandboxes as shown below.
{kind=link}
This will launch the link validation report showing the status of the links affected by the modifications made in the authors sandbox. This will therefore NOT check all links in the web project only those affected by the changes made by the author in his or her sandbox.
Progress Dialog
After clicking the 'Check Links' action and before the link validation report is launched the progress dialog is shown to give the user some feedback.
{kind=link}
The progress dialog will poll every 2 seconds to see whether the link validation check has completed and the report can be shown. The Configuration section below explains how to change the frequency of the checks.
Link Validation Report Dialog
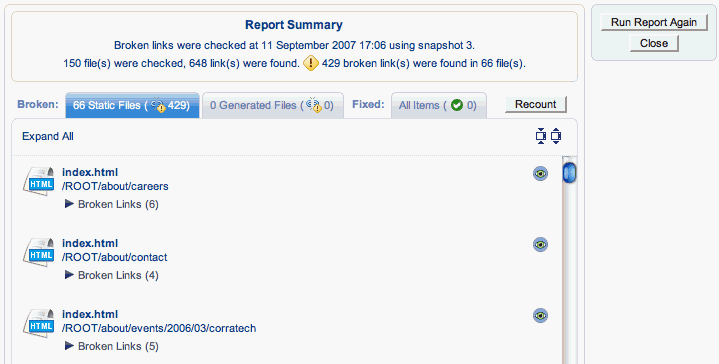
When a link validation check completes the link validation report dialog is launched, a typical report is shown in the screenshot below.
{kind=link}
As seen in the screenshot above the report consists mainly of a summary area and 3 tabs. The other items of interest are the buttons, resize icons and the Expand/Collapse All links. The sections below explain all these areas further.
Static Files Tab
This tab lists all the static files that contain broken links i.e. files added to the web project manually.
Each file that has been identified as containing a broken link is listed together with a list of (initially hidden) broken links. An expanded broken links section is shown below.
{kind=link}
If the report has been run in an authors sandbox each file will have an edit and preview action to the right hand side, these obviously allow the user to quickly see the page and then edit the file to potentially fix the broken links.
Generated Files Tab
This tab lists all the generated files that contain broken links i.e files generated from Forms.
If a file that has been identified as containing broken links is generated from a form, the form it was generated from will be listed. For each form the list of files it generated containing broken links is shown then for each generated file the list of broken links is shown, both of these lists are initially hidden. An expanded list of generated files is shown below.
{kind=link}
If the report has been run in an authors sandbox each form will have an edit action to the right hand side, this allows the user to quickly edit the form data that generated the forms and thus re-generate the files.
All Items Tab
This tab lists all the items that have been fixed since the report was initially shown.
As an author fixes up files and forms the 'Recount' button can be pressed, this will calculate which forms and files have been fixed, these will then be listed.
NOTE: If the 'Run Report Again' button is pressed all context is cleared therefore this tab will never be populated.
Buttons
There are 2 buttons present on the report, a 'Recount' button and a 'Run Report Again' button. The 'Recount' button is used to track progress as a user fixes links, pressing the button will run another link check and merge the results of the latest check with the initial check, items that have been fixed since the initial check will be shown in the 'All Items Tab'.
Resize Icons
The two resize icons (shown below) allow the size of the scrollable area to be increased and decreased. The icon on the left decreases the size of the scrollable area by 100 pixels (to a minimum of 100px). The icon on the right decreases the size of the scrollable area by 100 pixels.
{kind=link}
Expand/Collapse All Links
When the report is initially shown the broken links and in the case of generated files, the files, are shown in a collapsed state. All items can be expanded simultaneously by clicking the 'Expand All' link, conversely to collapse all items click the 'Collapse All' link. The hidden information can be shown or hidden for individual items by clicking the arrow icon next the item.
Configuration
The only configurable aspect of the links management UI is the polling frequency for the progress dialog, this is done via the web client configuration mechanism and as such can be overridden using the extension mechanism. web-client-config-wcm.xml contains the default value as shown below:
<links-management>
<progress-polling-frequency>2</progress-polling-frequency>
</links-management>
Debugging & Testing
Debugging for Link Management can be enabled in log4j.properties.
Remove the comment from the following line to enable debugging for the background process that continually checks a web projects links.
#log4j.logger.org.alfresco.linkvalidation.LinkValidationServiceImpl=debug
To enable debugging for the action that gets run when a link validation check is performed add the following line:
log4j.logger.org.alfresco.linkvalidation.LinkValidationAction=debug
To enable debugging for the link validation report dialog add the following line:
log4j.logger.org.alfresco.web.bean.wcm.LinkValidationDialog=debug
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Content Services Hub Docs
Ask for and offer help to other Alfresco Content Services Users and members of the Alfresco team.
Related links:
Latest Articles
- Alfresco Community Edition 201911 GA Release Notes
- Alfresco Community Edition 201910 EA Release Notes
- Deconstructing SOLR Indexes
- Alfresco Community Edition 201901 GA Release Notes
- Alfresco Community Edition 201808 EA file list
- php_upload.docx
- Alfresco Community Edition 201808 EA Release Notes
- Alfresco_6.0_docker deployment.pdf
- Alfresco Community Edition 201806 GA file list
- alfresco.log
- Alfresco Addons *Incomplete list*
- Alfresco Community Edition 201806 GA Release Notes
- AGS Benchmark Driver Documentation
- Default memory allocation issue in Alfresco CE 201...
- Alfresco Community Edition 201804 EA file list
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.