
Activiti & Activiti Cloud
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Alfresco Hub
- :
- APS & Activiti - Blog
- :
- Activiti & Activiti Cloud
Activiti & Activiti Cloud
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
22 Aug 2017
8:15 AM
After a week of moving things around, we are reaching a point where we can share the new structure of our projects and repositories. The changes introduced highlight the different nature of each of these projects and how are they going to be used and consumed. The changes are now considered stable and unless we find very good reason for a new re-organization, these repositories will be considered as part of the Activiti 7 project main efforts.
Conceptually, you will find that there are 3 main layers:

The Core layer will always contain Java Frameworks, in this case, the Activiti/Activiti repository will host the Process Engine that you can embed in your own applications as any other java dependency. While this is enough for some cases, it requires you to build a significant layer of integration and make some complicated decisions about your runtime. I’ve seen such implementations fall into two main categories:
- The engine embedded in the application: this approach has major drawbacks regarding footprint of your application, memory consumption and adding too much responsibility.
- The engine embedded in a service layer: this approach is better, but it pushes you to define this service layer. Some companies use this layer to make sure that they don’t depend on a process engine, but this is costly and takes a lot of time to get it right
The same applies to the Query and Audit modules, which are now hosted in the same repository, but we might want to move those away in a future refactoring.
The next new layer that we are providing in Activiti is the Service Layer. As mentioned before, we want to avoid you having to implement this Service wrapper on top of the Engine. For that reason, we have created a modern REST HAL API and Message-Based Endpoints that can be easily extended and adapted to your needs. These Services are designed and implemented in isolation to make sure that they follow the single responsibility approach. We now provide the following services:
- Process Engine
- Audit Service
- Query Service
This list will be expanded in the future with more services, and we will make sure that our services doesn’t overlap functionality that is already provided by the infrastructure or other popular components that you might be already using. A typical example for avoiding overlap, in this case, is the new SSO/IDM component that we are using. We are not providing any homegrown SSO/IDM mechanism as most of the BPM engines out there do. Instead, we are delegating that responsibility to a component that has been designed for providing that integration layer with SSO and IDM specific implementations.
Finally, our last layer is the Infrastructure layer. Our new infrastructure layer allows us to provide a simple way to bootstrap all these services in a cloud-oriented way. We recognized that most of our users aim to run these services on existing infrastructure and for us, it is important to make their lives easier. This infrastructure layer is based on Spring Boot, Spring Cloud, Docker and Kubernetes, relying on and reusing all the services that they provide so our services can scale independently. Once again, by aligning our services to these technologies we wanted to make sure that we don’t overlap with the features that they provide. We want our users to feel that when they adopt Activiti, they don’t need to change their infrastructure or the way that they do things in their other services.
The Repositories
Under the Activiti organization in Github we have created several repositories to represent these layers. These repositories are linked in our CI servers and arrows in the following diagram means downstream dependency. Every time that we make a change in the core engine all the services will need to be built and test again.
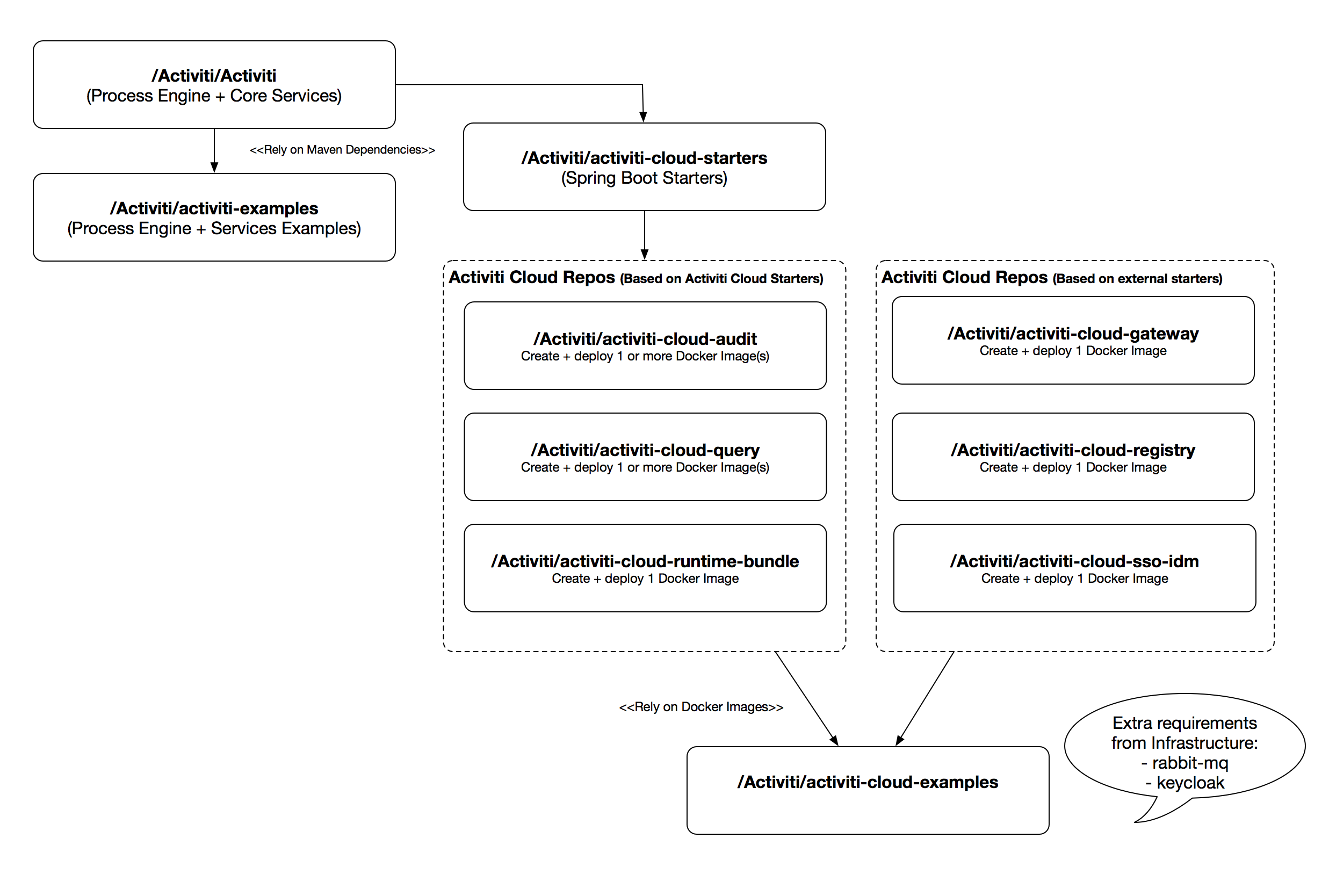
Notice also, that all the repositories that depends on *-starters are going to generate and publish Docker Images to Docker Hub, meaning that you will be able to consume all these infrastructure without the need of compiling a single Java class.
Our activity-cloud-examples repository will provide examples that show how to bootstrap the whole infrastructure in your dev environments and existing cloud infrastructures.
One more important thing to understand is that we recognise that each implementation will probably want to replace one or more of these components, so you can end up using the example implementation as reference to implement your own components. If you think that one of your components might benefit the whole community then please get in touch- we can help each other with the design and implementation.
Here are some of the links to our new repositories, Docker Hub and our Travis-CI builds:
Core and Core services repository
https://github.com/Activiti/Activiti
Docker Hub Activiti organization
https://hub.docker.com/u/activiti/dashboard/
Activiti Cloud related repositories
https://github.com/Activiti/activiti-cloud-starters
https://github.com/Activiti/activiti-cloud-runtime-bundle
https://github.com/Activiti/activiti-cloud-query
https://github.com/Activiti/activiti-cloud-audit
https://github.com/Activiti/activiti-cloud-registry
https://github.com/Activiti/activiti-cloud-gateway
https://github.com/Activiti/activiti-cloud-sso-idm
Activiti Cloud Examples
https://github.com/Activiti/activiti-cloud-examples
Travis CI public builds
https://travis-ci.org/Activiti/
New Approach / New Scenarios
You might have notice that we now have more services, more things to manage, possible different types of storage. Clearly the way of using the Process Engine is changing. This new approach will open the door to new scenarios, scenarios where we don’t work against a single clustered process engine. Scenarios where we want different components to emit events that will be aggregated by other components such as the Query and Audit service. Each of these different scenarios might have different requirements such as the use of NoSQL data stores to support graph based data or json documents for search and indexing. This new approach will also allows us to scale different parts of our infrastructure separately and responsively.
Because of that all our services are dockerized and will require an orchestration layer to wire them together. The next section provides a quick intro to these docker images and how to get all the infrastructure up and running by following the activiti-cloud-examples.
A (docker) image worth more than 1000 words
We have now 6 (docker) images published on docker hub and you can get them all up and running in just a couple of minutes. The following diagram shows set of services started when you follow the README file in the activiti-cloud-examples repository:

Notice that Cloud Connectors are not there yet. The client application represent your other microservices that might share the same infrastructure as Activiti. And Databases related to each services are omitted for simplicity, but the Runtime Bundle docker-compose is starting a PostgreSQL DB.
Also notice that the communication between these components is likely to happen in an asynchronous way, and for that reason we are also starting RabbitMQ as our message broker. Because we are relying on Spring Cloud Streams, the provider (binder) can be replaced with by some other providers such as Kafka and Active MQ.
From a client/developer side, you only need docker to get all up and running in a couple of minutes. No java or maven is required to build your domain specific runtime bundles.
You can use the (chrome plugin) postman collection to test the services endpoints.
We will be working hard to make sure that we provide tools to package and version runtime bundles to make sure the the whole process of building and deploying these images is smooth and fast.
More blog posts about Runtime Bundles are coming, which is a central concept in the new infrastructure.
If you are interested, have questions, comments or if you want to participate in all these changes please get in touch. You can join us everyday in our Gitter channel, where we have open discussions about how each of these components are implemented.
Stay tuned!
Original Blog post: https://salaboy.com/2017/08/22/activiti-activiti-cloud/
Labels
About the Author
Open Source, Java, BPM and Rule Engine enthusiast and promoter. Writer of 4 books about BPM & Rule Engines, now Principal Software Engineer @ Alfresco.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Alfresco Process Services Blog
Blog posts and updates about Alfresco Process Services and Activiti.
Latest Articles
- Activiti Cloud 7.1.0.M2 released!
- Alfresco Process Services SDK Maven Module
- Activiti Updates, Just in Time for Summer
- New OSS challenges ahead
- Activiti Cloud 7.1.0.M1 released!
- Activiti: Last week Dev Logs #87
- Activiti: Last week Dev Logs #86
- Activiti Cloud SR1 Released!
- Activiti: Last week Dev Logs #85
- Activiti: Last week Dev Logs #84
- Activiti: Last week Dev Logs #83
- Activiti Cloud 7.0.0.GA Released
- Activiti: Last week Dev Logs #82
- Activiti: Last week Dev Logs #81
- Activiti Cloud @ DevCon 2019
We use cookies on this site to enhance your user experience
By using this site, you are agreeing to allow us to collect and use cookies as outlined in Alfresco’s Cookie Statement and Terms of Use (and you have a legitimate interest in Alfresco and our products, authorizing us to contact you in such methods). If you are not ok with these terms, please do not use this website.